All content is from public documents and open source projects.
Brief Introductions
The Architecture of Big Data Processing
Lambda
Refer to What Is Lambda Architecture?
The Lambda Architecture contains both a traditional batch data pipeline and a fast streaming pipeline for real-time data, as well as a serving layer for responding to queries.
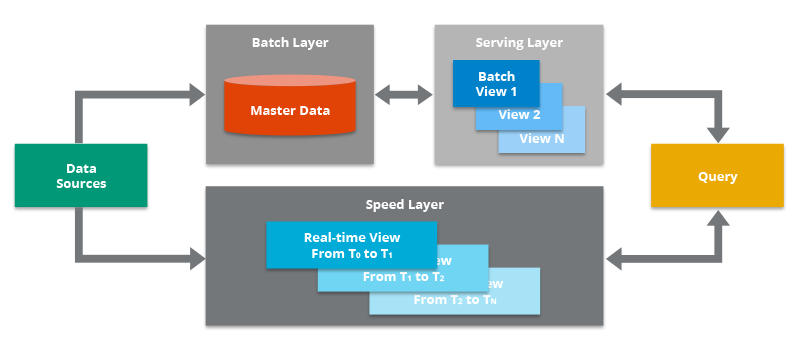
In the Data Sources, Kafka are oftentimes acted as an intermediary store, though it is not the original data source.
In the Batch Layer, the processed data is treated as immutable and append-only to ensure a trusted historical record of all coming data. A technology like Apache Hadoop is often used as a system for ingesting the data as well as storing the data in a cost-effective way.
In the Serving Layer, it incrementally indexes the latest batch views to make it queryable by end users.
In the Speed Layer, it complements the Serving Layer by indexing the most recently added data not yet fully indexed by the serving layer. This includes the data that the serving layer is currently indexing as well as new data that arrived after the current indexing job started.
In the Query Layer, it is responsible for submitting end user queries to both the serving layer and the speed layer and consolidating the results.
Once a batch indexing job (in the Batch and Serving Layer) completes, the newly batch-indexed data is available for querying, so the speed layer’s copy of the same data/indexes is no longer needed and is therefore deleted from the speed layer.
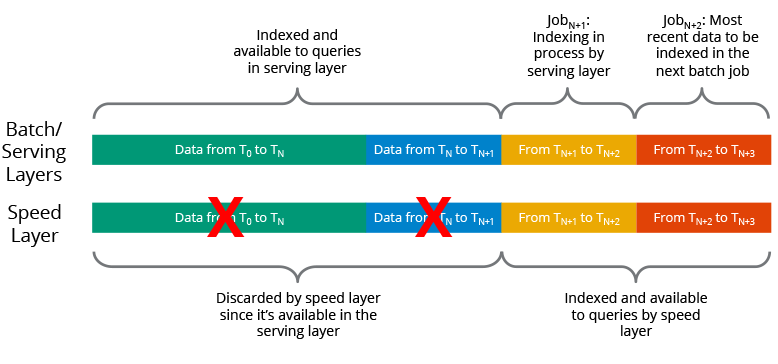
The benefits of this architecture are as shown below.
- Low latency.
- Due to existence of the speed layer.
- Data consistency.
- In a distributed database where data might not be delivered to all replicas due to node or network failures, there is a chance for inconsistent data. In other words, one copy of the data might reflect the up-to-date value, but another copy might still have the previous value.
- In the Lambda Architecture, since the data is processed sequentially (and not in parallel with overlap, which may be the case for operations on a distributed database), the indexing process can ensure the data reflects the latest state in both the batch and speed layers. (I don't quiet understand this. In my understand, only when the batch Layer completes a batch, this part of data will be used in for query. So query will not use the intermediate state of the data).
- I think Delta can ensure the data consistency too.
- Scalability.
- Both Batch Layer, Serving Layer and Speed Layer can process data parallelly.
- Fault tolerance
- This is the ability of batch layer and serving layer and the speed layer continue indexing the most recent data.
- Human fault tolerance
- The index can be recreated.
The disadvantages are also obvious. we need maintain two sets of code with the same processing logic in the batch/serving layer and speed layer.
Kappa
The main premise behind Kappa Architecture is that you can perform both real-time and batch processing, especially for analysis, with a single technology stack, which is the biggest advantage over Lambda architecture. It is based on a streaming architecture, as it shown below.
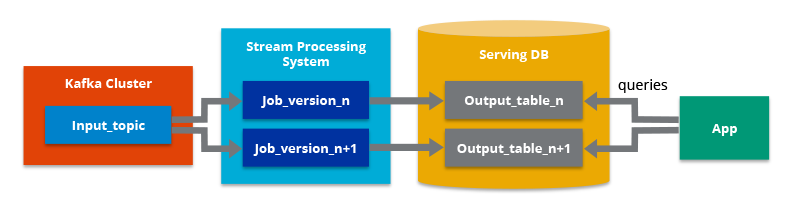
The role of Serving DB is usally played by the Redis or Elastic Search whose cost is high.
When the full data is needed, Kappa will use the stream processing engine to start consumption from the earliest position of the message queue to build the full amount of data.
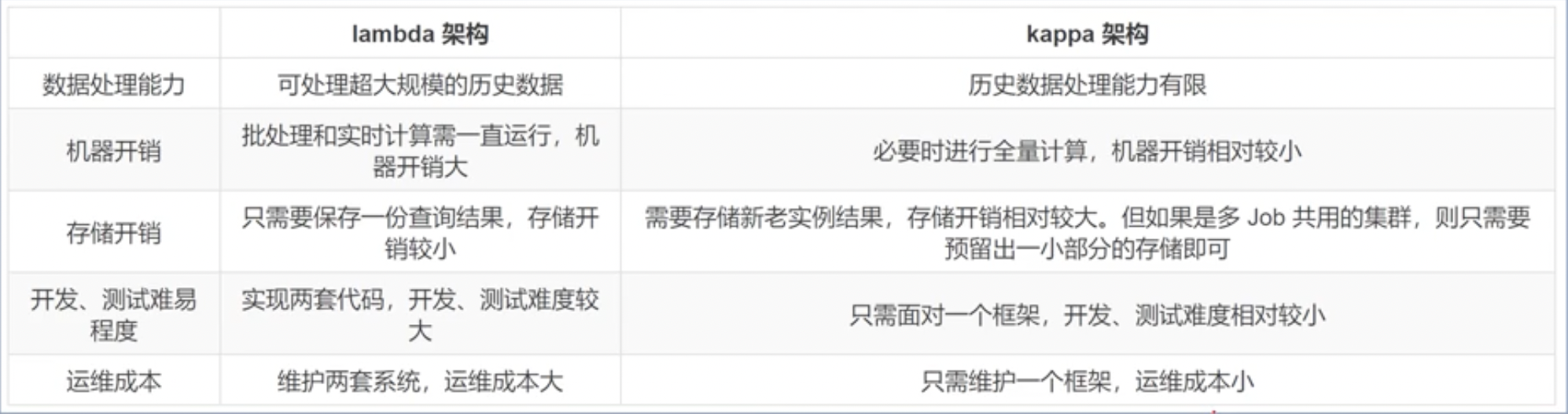
The differences between Lambda and Kappa are as shown below.
Data Warehouses
For analyzing structured or semi-structured data. They were purpose-built for BI and reporting, however,
- No support for video, audio, text
- No support for data science, machine learning
- Limited support for streaming
- Closed & proprietary formats
Data Lakes
For storing data at scale. They can handle all data for data science and machine learning, however,
- Poor BI support
- Complex to set up
- Poor performance (operation based on files)
- Unreliable data swamps
Databricks
It is one remarkable unified analytics platform that combines the benefits of both Data Lake and Data Warehouse by providing a Lake House Architecture. Lake House (Data Lake + Data WareHouse) Architecture built on top of the data lake is called Delta Lake. Below are a few aspects that describe the need for Databricks’ Delta Lake:
- It is an open format storage layer that delivers reliability, security, and performance on your Data Lake for both streaming and batch operations.
- It not only houses structured, semi-structured, and unstructured data but also provides Low-cost Data Management solutions.
- Databricks Delta Lake also handles ACID (Atomicity, Consistency, Isolation, and Durability) transactions, scalable metadata handling, time travel handling and data processing on existing data lakes.
Parquet
It is a columnar storage format available to any project in the hadoop ecosystem, regardless of the choice of data processing framework, data model or programming language.
Detailed Introductions
Databricks
ACID Transaction
ACID transaction guarantees is provided by Databricks as a layer of storage on the basis of data lake. This means that:
- Multiple writers across multiple clusters can simultaneously modify a table partition and see a consistent snapshot view of the table and there will be a serial order for these writes.
- Readers continue to see a consistent snapshot view of the table that the Azure Databricks job started with, even when a table is modified during a job.
Delta Lake (Databricks) uses optimistic concurrency control to provide ACID transaction guarantees. Under this mechanism, writes operate in three stages:
- Read: Reads (if needed) the latest available version of the table to identify which files need to be modified (that is, rewritten).
- Write: Stages all the changes by writing new data files.
- Validate and commit: Before committing the changes, checks whether the proposed changes conflict with any other changes that may have been concurrently committed since the snapshot that was read. If there are no conflicts, all the staged changes are committed as a new versioned snapshot, and the write operation succeeds. However, if there are conflicts, the write operation fails with a concurrent modification exception rather than corrupting the table as would happen with the write operation on a Parquet table.
The default isolation level of delta table is defined as Write Serializable.