Here is a note recorded by YW.
Playground
Scripts provided in Debezium with MySQL Playground GitHub can help build a test environment quickly.
Transaction Isolation Level
InnoDB offers all four transaction isolation levels described by the SQL 1992 standard: READ_UNCOMMITTED, READ_COMMITTED, REPEATABLE_READ, and SERIALIZABLE.
There is question, when does a transaction start, a
beginstatement? no! A transaction starts when the first statement which operates the InnoDB table executes, or usestart transaction with consistent snapshotstatement to start a transaction.
REPEATED_READ (RR)
This is the default isolation level for InnoDB. It is implemented through MVCC (implemented in undo log) and Gap Lock (or Next-key Lock the combination of Record Lock and Gap Lock) which has below features:
Consistent reads within the same transaction read the snapshot established by the first read. This is supported by Consistent NonLocking Reads. This can be called snapshot read.
Consistent NonLocking Reads means that InnoDB uses multi-versioning (I think this is multi-version concurrency control short for MVCC) to present to a query a snapshot of the database at a point in time (please note the time is when executing query statement, not when starting a transaction). The query sees the changes made by transactions that committed before that point in time, and no changes made by later or uncommitted transactions. The exception to this rule is that the query sees the changes made by earlier statements within the same transaction.
Mysql Doc also mentioned below, which confused me. This exception causes the following anomaly: If you update some rows in a table, a SELECT sees the latest version of the updated rows, but it might also see older versions of any rows. If other sessions simultaneously update the same table, the anomaly means that you might see the table in a state that never existed in the database.
Answer: pending to verify. According to the time when a snapshot is determined, if we change data firstly after we start a transaction A, secondly update data and commit in another transaction, finally select rows in transaction A and we will see a state that never existed in the database. Below is an example, it also can prove that the time when a snapshot is determined is the time when query statement is executed.
For locking read( SELECT with FOR UPDATE or FOR SHARE) which called current read, UPDATE, and DELETE statement, locking depends on whether the statement uses a unique index with a unique search condition, or a range type search condition.
- For a unique index with a unique search condition, InnoDB locks only the index record found, not the gap before it.
- For other search conditions, InnoDB locks the index range scanned, using gap locks or next-key locks to block insertions by other sessions into the gaps covered by the range.
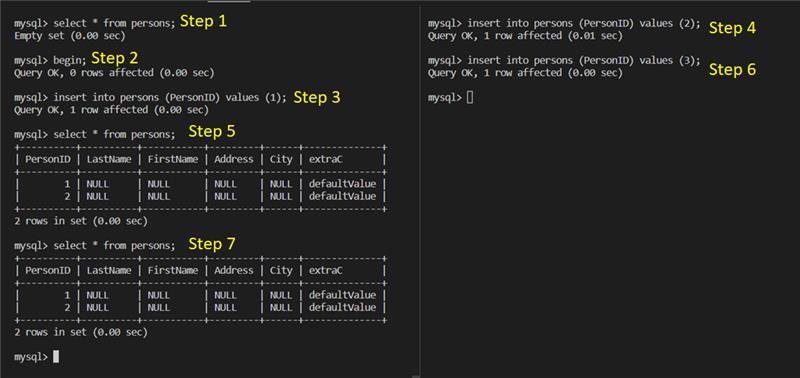
There are some examples, as shown below. Through below examples, understand when a consistent read view will be created and the difference between snapshot read and current read.
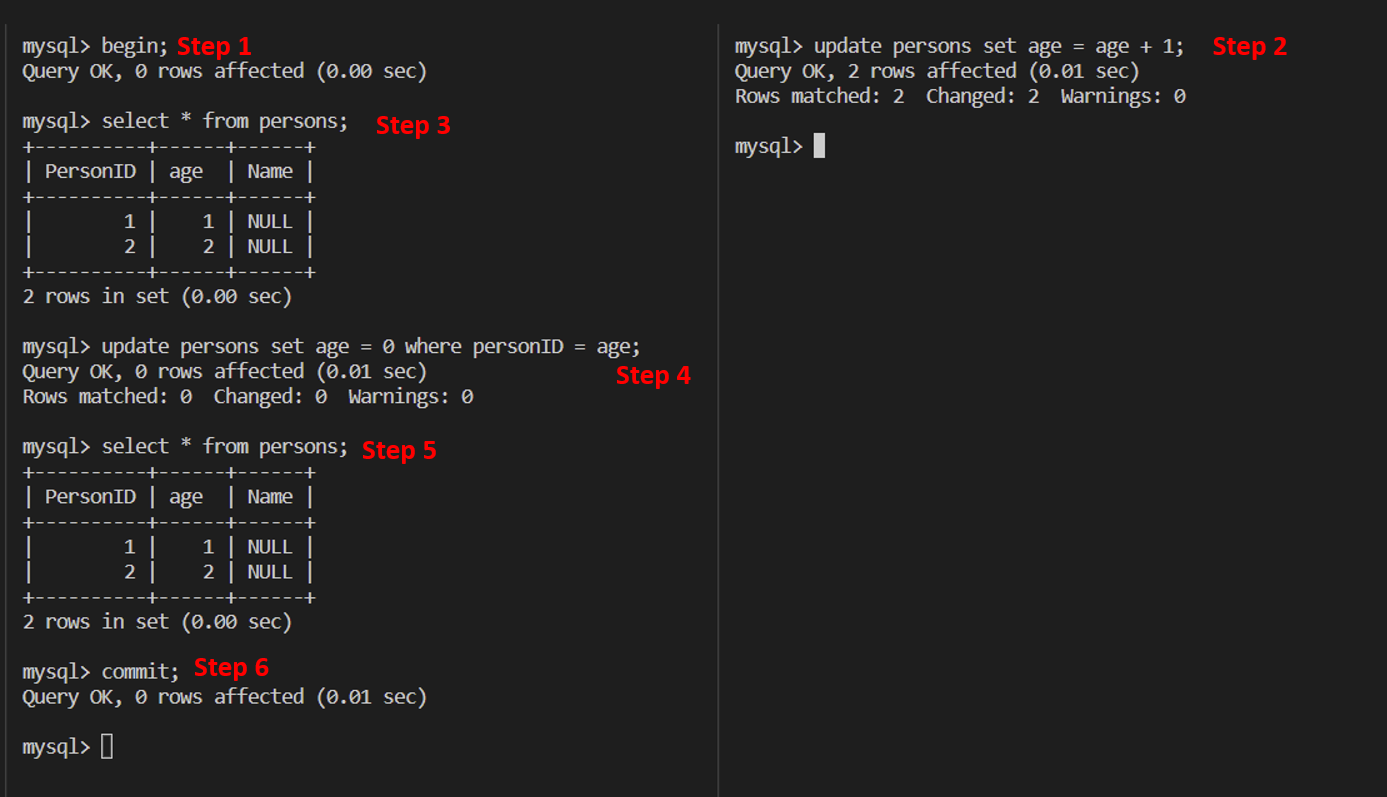
Example 1
It shows that when executing start transaction statement, the consistent read view has not been created.
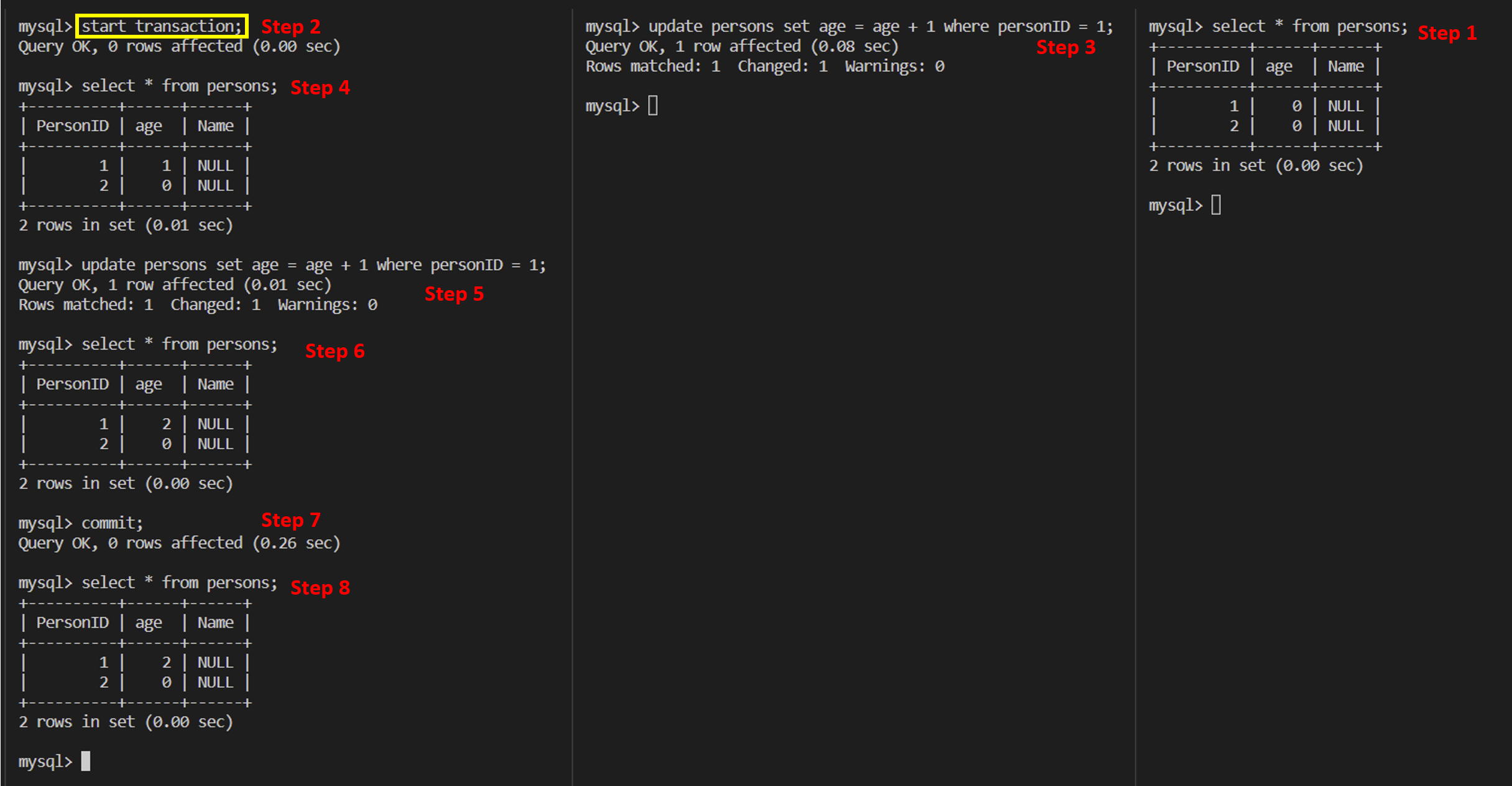
Example 2
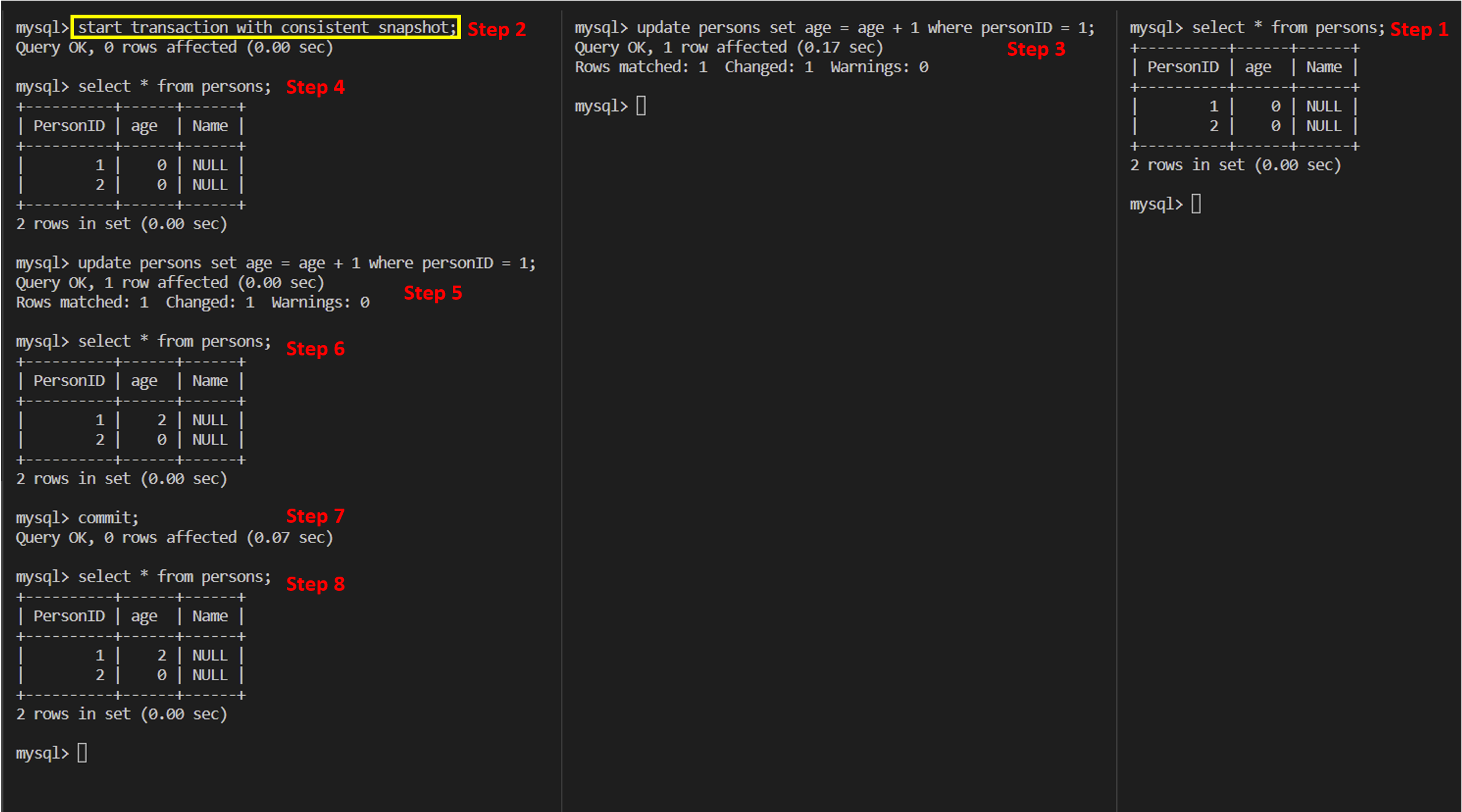
It shows that when executing start transaction with consistent snapshot statement, the consistent read view will be created. But the consistent read view is only for snapshot read, but will not be used by update statement, which means the logic of reading value in update statement is not the same with select statement, but the same with select ... lock in share mode or select ... for update shown in ex 3 and ex 4. The logic of reading value in update statement or for update statement is that the change needs relying on the latest version in committed versions, which is called current read.
Example 3
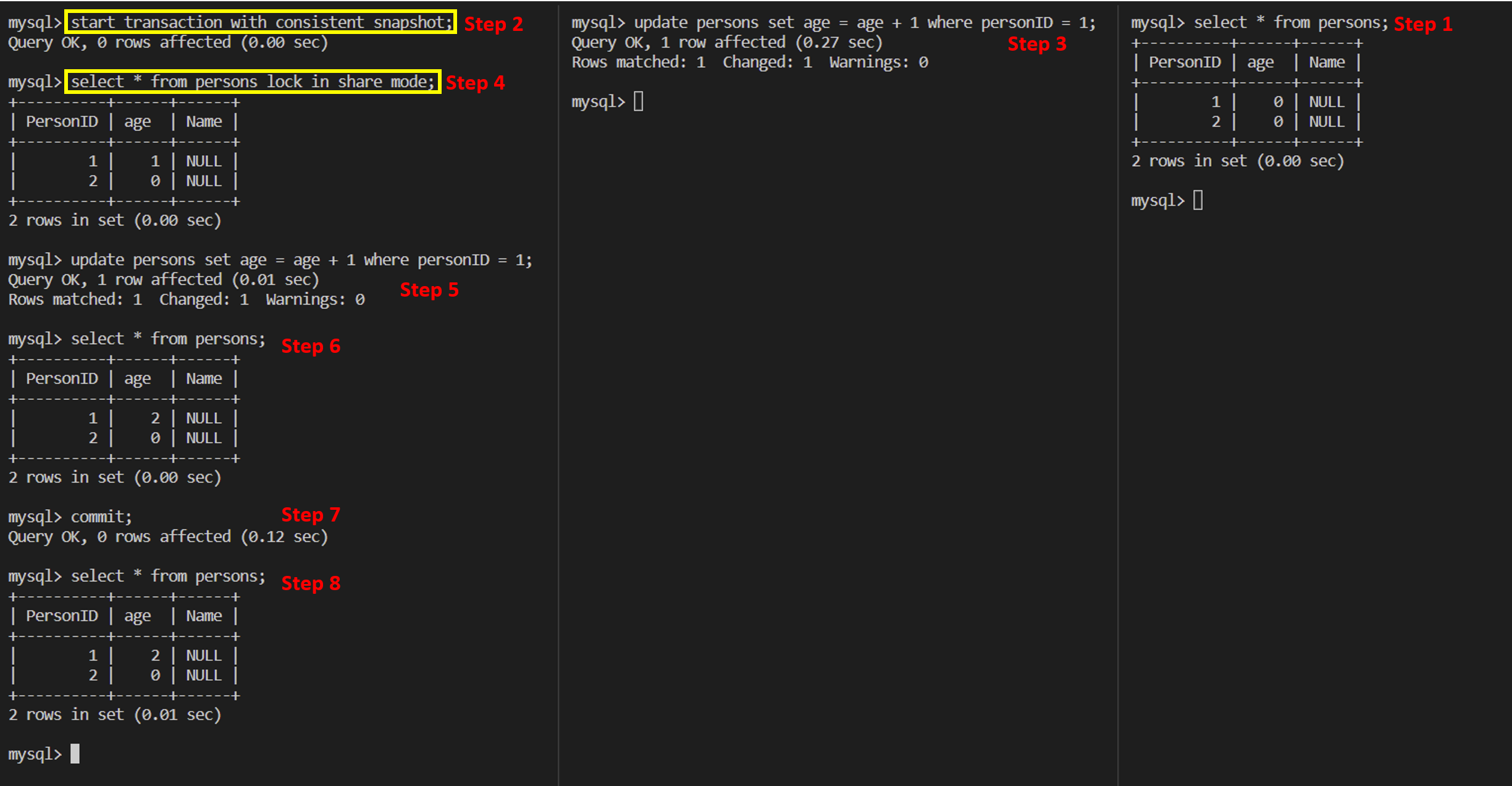
Question:
lock in share modeis related with a shared lock but not a exclusive lock. Why does it still use the current read mode?Answer: In official documentation,
lock in share modeis called locking read, which are the same type withselect for update,updateanddelete.
Example 4
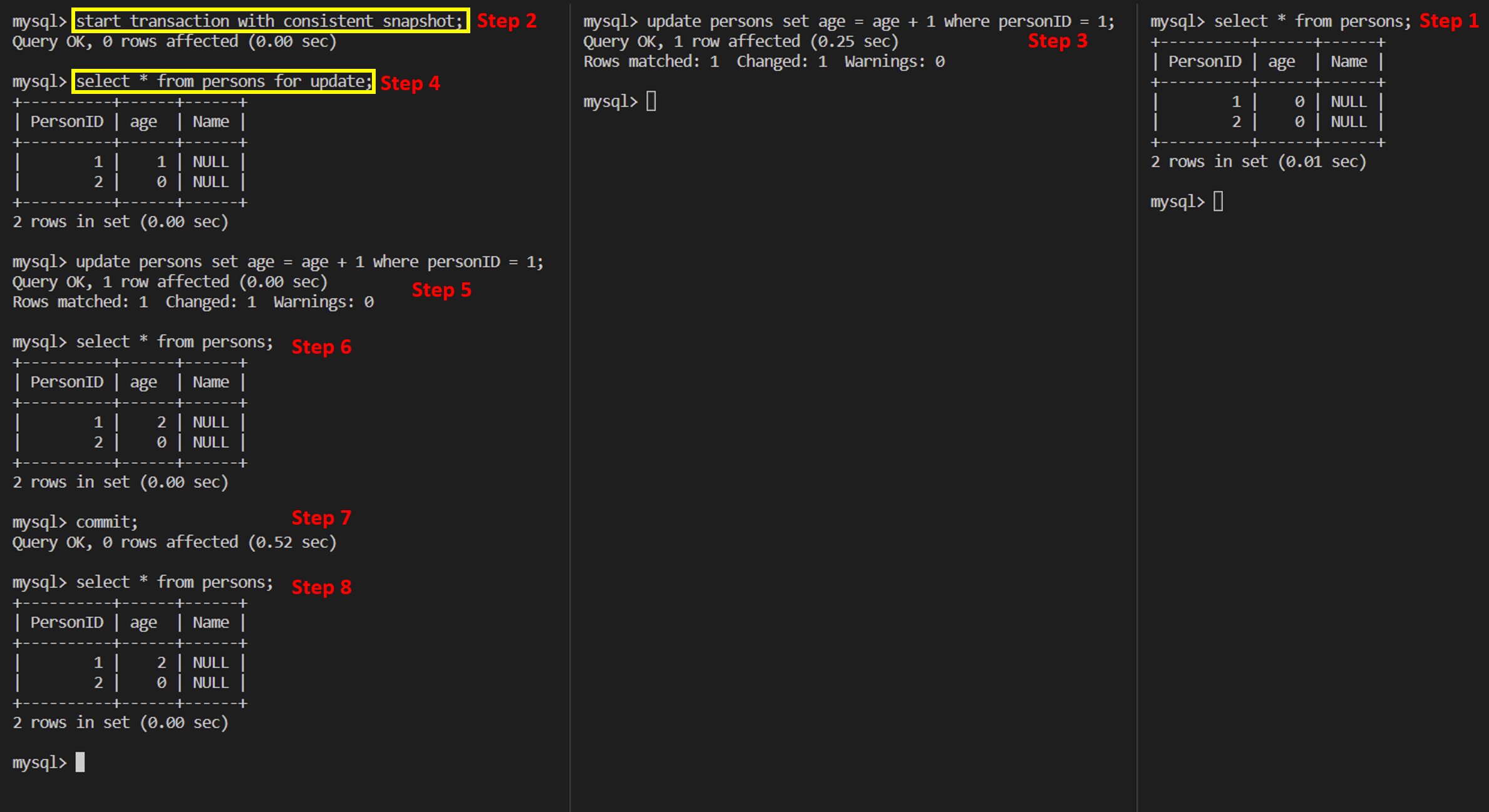
Example 5
It shows that the consistent read view will be created when the first select statement executed, even if update statement was executed before.
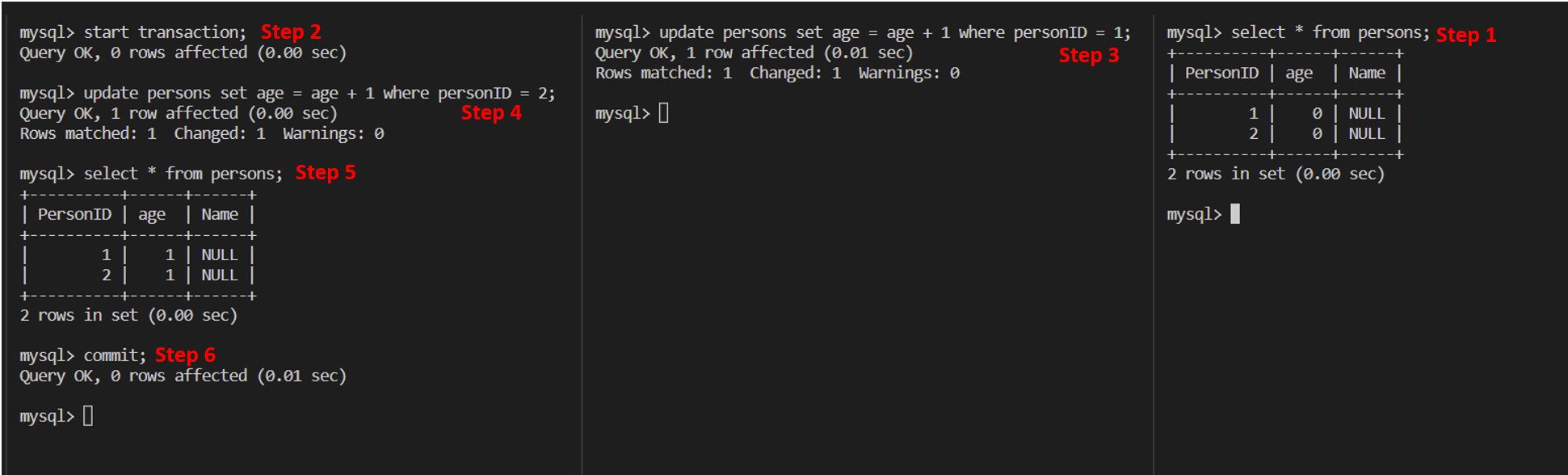
Example 6
Based on the difference with snapshot read and current read, there is an interesting example. Through this example, please note that if you want to change data, you must use current read, but not snapshot read.
Note: The step 3 can see the changes made by step 2. Refer to ex 1 and ex 5.
READ_COMMITTED (RC)
There are no scenario which can enable me to learn. # InnoDB Locks
There are many types of lock.
InnoDB Locks Type
Shared and Exclusive Locks
They are two standard row-level locking.
- A shared (s) lock permits the transaction that holds the lock to read a row. Shared lock can be shared between transaction which want to read.
- An exclusive (x) lock permits the transaction that holds the lock to update or delete a row. Exclusive can't be shared to any other transaction.
Intention Locks
This locks are table-level locks that indicate which type of lock (shared or exclusive) a transaction requires later for a row in a table. There are two types of intention locks:
- An intention shared lock(IS) indicates that a transaction intends to set a shared lock on individual rows in a table.IS can be set by
SELECT ... FOR SHARE - An intention exclusive lock(IX) indicates that a transaction intends to set an exclusive lock on individual rows in a table. IX can be set by
SELECT ... FOR UPDATE
The intention locking protocol is as follows:
- Before a transaction can acquire a shared lock on a row in a table, it must first acquire an IS lock or stronger on the table.
- Before a transaction can acquire a exclusive lock on a row in a table, it must first acquire an IX lock on the table.
Record Locks
A record lock is a lock on an index record, preventing any other transaction from inserting, updating or deleting rows which is locked by record locks.
Gap Locks
A gap lock is a lock on a gap between index records, or a lock on the gap before the first or after the last index record. It prevents other transactions from inserting a row into the gap, whether or not there was already any such value in the column, because the gaps between all existing values in the range are locked.
Next-Key Locks
They are a combination of record lock and gap lock, which lock a gap left open and right closed (].
Insert Intention Locks
An insert intention lock is a type of gap lock set by INSERT operations prior to row insertion, which signals the intent to insert in such a way that multiple transactions inserting into the same index gap need not wait for each other if they are not inserting at the same position within the gap. E.g., there are index records with value 4 and 7, and seperate transactions that attempt to insert values of 5 and 6, respectively, each lock the gap between 4 and 7 with insert intention locks prior to obtaining the exclusive lock on the inserted row, but do not block each other because the rows are nonconflicting.
Why need take an insert intention lock prior to obtaining an exclusive lock on the inserted record?
Because insert intention lock and exclusive lock can form an exclusive relationship, which is very helpful in below scenes.
Client A:
1 | mysql> START TRANSACTION; -- No.1 |
Client B:
1 | mysql> START TRANSACTION; -- No.3 |
The No.4 statement is blocked by Client A and Client A can execute insert operation at id in range of (100, null) prior to Client B. Through SHOW ENGINE INNODB STATUS you can see
1 | RECORD LOCKS space id 31 page no 3 n bits 72 index `PRIMARY` of table `test`.`child` |
Auto-INC Lock
An AUTO-INC Lock is a special table-level lock taken by transactions inserting into tables with AUTO_INCREMENT columns. Through innodb_autoinc_lock_mode variable can set the lock mode to use for generating auto-increment values. The lock mode includes traditional, consecutive and interleaved. refer to 14.7.2.3 Consistent Nonlocking Reads for more.
Predicate Locks for Spatial Indexes
A SPATIAL index contains minimum bounding rectangle (MBR) values, so InnoDB enforces consistent read on the index by setting a predicate lock on the MBR value used for a query. Other transactions cannot insert or modify a row that would match the query condition. This is not used by me now.
Questions
Some issue about locks
The order of acquire locks?
InnoDB Locking Principle
Only limit in MySQL version 5.7, innoDB engine and REPEATED READ isolation level. Firstly describe a table for the convenience of the following example. The id column is a primary key, c column is a no unique index and no index on d column as shown below
1 | CREATE TABLE `t` ( |
Principle 1: Consider adding next-key locks firstly.
Principle 2: Locks only exist on scanned rows.
Optimize 1: The next-key locks will weaken to record locks when querying on unique index with equivalent condition.
There is an example ex 1. If query table
twith statementselect * from table t where id = 10 for update, it will lock index id with record lock 10. please note that this is because there is a row with id 10 existing in table, if not the origin next-key lock according principle 1 will not weaken to record lock.Optimize 2: The next-key locks will weaken to gap locks when the right boundary of next-key locks is not equal to the value in equivalent condition.
There is an example ex 2. If query table
twith statementselect * from t where c = 12 for update, it will lock index c with next-key lock (10, 12] and gap lock (12, 15) which is a weakness from next-key lock (12, 15] according to principle 1.There is another example ex 3. If query table with statement
select * from t where id = 7 for update, it will lock index id with gap lock (5, 10) which is a weakness from next-key lock (5,10] according principle 1 because 7 is not equal to 10. Please compare this with ex 1.Bug 1: Access until the first value of the condition is not met when a range query on a unique index.
Test about Transaction and Locks
MySQL Logs
There are six types of logs in MySQL, which play an important role in the core functions of MySQL. They are error logs, query logs, slow query logs, transaction logs(including redo log and undo log) and binary logs(binlog). Understanding them is very helpful for us to use MySQL and below is show some information I learned.
Binlog
It is used to record write operation in MySQL and be saved in binary format file. It is logic log of MySQL and recorded by server layer, which is not necessary and we can choose to disable it.
Binlog is a part of Mysql which exists from the beginning and is the base for MySQL's high availability. However Redo Log is a part of InnoDB which is the key to support crash recover. InnoDB is not Mysql's native storage engine. MySQL's native storage engine is MyISAM which is not support crash recover.
Here is a statement from the official documentation on the relationship between transaction commit order and binlog write order.
Binary logging is done immediately after a statement or transaction completes but before any locks are released or any commit is done. This ensures that the log is logged in commit order.
However, no clear statements about the order of timestamps in binlog and the order of other fields have been found in the official documentation. A survey on the order of certain fields will be listed below.
Usage Scenarios
Binlog is used for two important purpose:
- Replication, also as known as Master-slave replication.
- Data Recovery: Use
mysqlbinlogtools to recover data.
Features
All events belonging to one transaction will be saved in one log file and never will be split into two or more files. This also will cause the size of some log file is larger than the declared size (
max_binlog_size).A client that has privileges sufficient to set restricted session system variables can disable binary loggings of its own statements by using a
SET sql_log_bin=OFF.There is a chance that the last statements of the binary log could be lost. Such an issue can be resolved assuming
sync_binlogis set to1.sync_binlogis configured to synchronize the binary log to disk after every N commit groups. Refer to link.There is a chance that the logs of a transaction are recorded but the database rollback the transaction actually. Such an issue can be resolved assuming
innodb_support_xais set to1. >innodb_support_xais related to the support of XA transaction in InnoDB and it also ensures that the binary log and InnoDB data files are synchronized. Refer to link. > >innodb_support_xais deprecated. InnoDB support for two-phase commit in XA transaction, which is always enabled as of MySQL 5.7.10
Binlog Logging Formats
There are three logging formats shown as below, and row is the format I am using.
STATEMENT
It is statement-based replication (SBR), All SQLs which modified data will be recorded in binlog, which is a small size. But there may be issues with replicating nondeterministic statements. Statement may not be safe to log in statement format. BTW, this is the default format before v5.7.7.
ROW
It is row-based replication (RBR), which only record the data which be modified and indicates how individual table rows are affected. But its size is very big. If using this format, it's very important that tables always use primary key to ensure rows can be efficiently identified. Debezium can parse the before and after state of a changed entity (a row in MySQL table) from this type of binlog. BTW, this is the default format after v5.7.7.
There are some important parameters related to this format, which is also related with Debezium:
- TODO:
MIXED
It is based on mixed-based replication (MBR), which based on STATEMENT and ROW format.
Timestamp about Transaction
Here is an example to show.
Environment: Mysql 5.7 Binlog Row Format.
Execute SQL
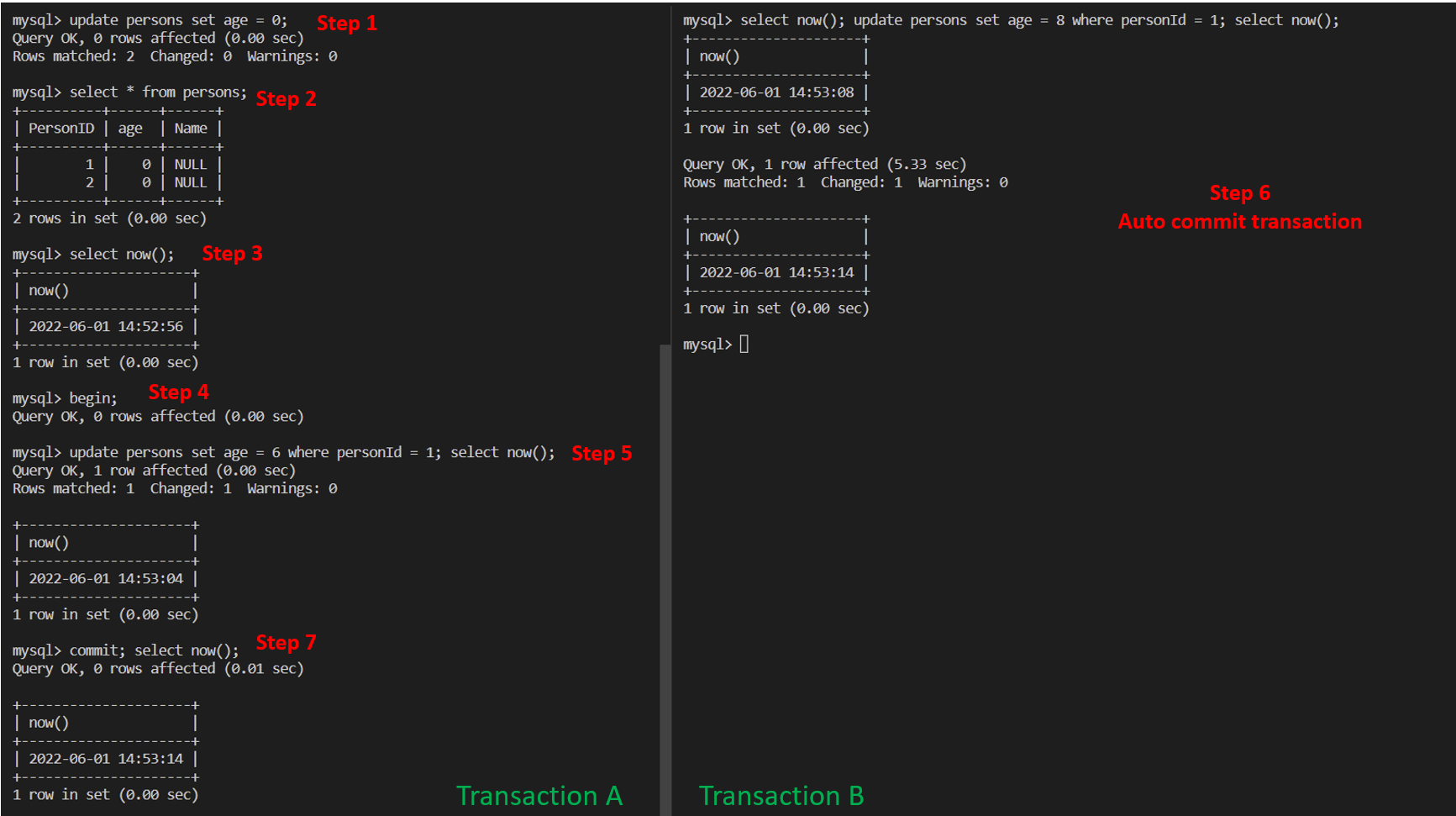
Binlog Timestamp
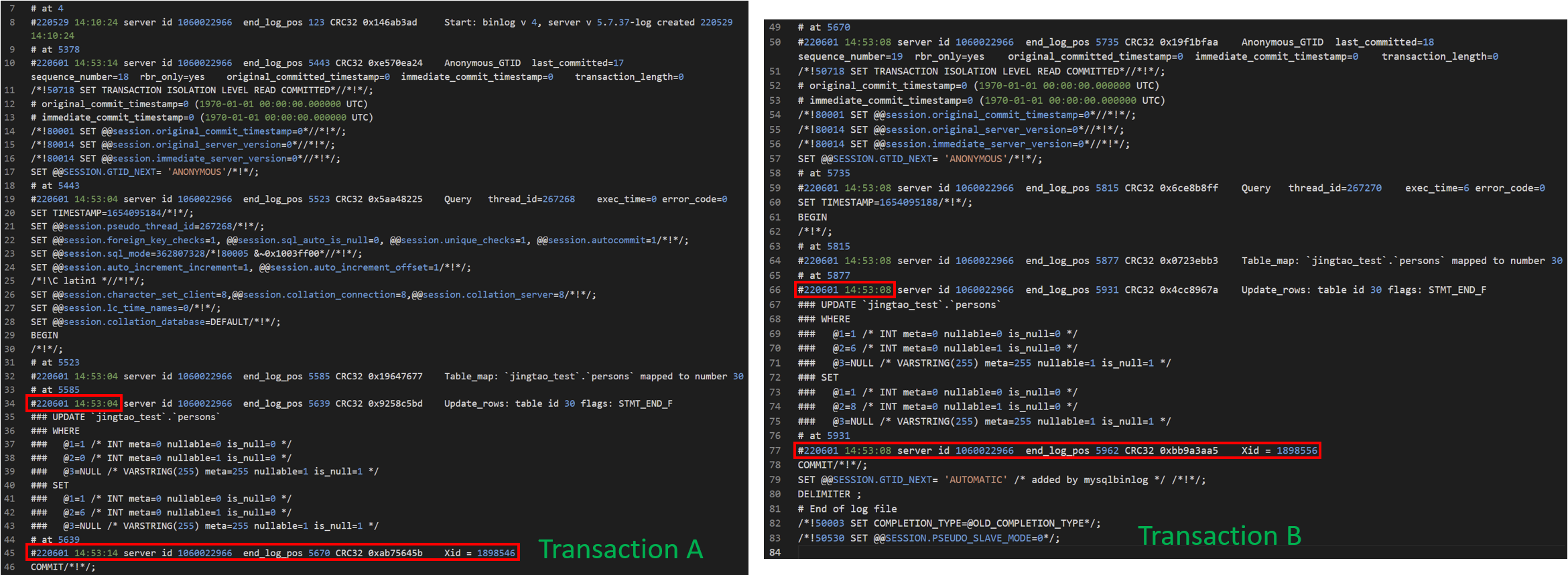
Through above experiment, I found that
- the transaction commit timestamp of manually commit transaction is when
commitcommand was executed. - the transaction commit timestamp of automatically commit transaction when the single statement was executed, which does not reflect the actual commit timestamp.
- the timestamp of update record is when
updatestatement was executed.
So, The timestamps of transaction Xid events maybe are not ordered.
Xid Events about Transaction
Xid IDs are assigned when the transaction starts, but transaction started first is not necessarily committed first.
So, The ID of transaction Xid events maybe are not ordered.
GTID about Transaction
The official document has the following introduction. GTID is the abbreviation of Global Transaction Identifier. When using GTIDs, each transaction can be identified and tracked as it is committed on the originating server and applied by any replicas. And it's not necessary to refer to log files and positions within those files when starting a new replica or failing over to a new server. Because GTID-based replication is completely transaction-based, it is simple to determine whether sources and replicas are consistent. As long as all transactions committed on a source are also committed on a replica, consistency between the two is guaranteed.
The format of GTID is shown as below. The source_id identifies the originating server, and the transaction_id is a sequence number determined by the order in which the transaction was committed on the source.
1 | GTID = source_id:transaction_id |
The upper limit for sequence numbers for GTIDs on a server instance is the number of non-negative values for a signed 64-bit integer (2 to the power of 63 minus 1, or 9,223,372,036,854,775,807). If the server runs out of GTIDs, it takes the action specified by binlog_error_action.
Question: Why is the GTID sequence number signed?
Answer: This answer is generated by GitHub CoPilot, pending to verify.
Because the sequence number is used to identify the transaction, and it is possible that a transaction may be committed on the originating server before it is committed on the replica. In this case, the transaction ID is negative.
GTID has the following features:
- It is a unique identifier for each transaction across all servers in a given replication topology.
- Monotonic increasing without gaps between the generated numbers on the server of origin. > If a transaction was filtered out, or was read-only, it is not assigned a GTID. > Only
- It can be used to distinguish between client transactions, which are committed on the source, and replicated transactions, which are reproduced on a replica.
- Replicated transactions retain the same GTID that was assigned to the transaction on the server of origin.
- It can be used to ensure that a transaction committed on the source can be applied no more than once on the replica.
- It can be used to stop the concurrent execution of transactions with the same GTID.
But GTID can't distinguish the order of transactions when master-slave switches.
Redo Log
It is designed for durability feature in ACID, using a technique called Write-Ahead Logging (WAL). Relying on Redo Log can achieve cash recover.
Undo Log
It is designed for automatic feature in ACID. Multi version concurrency control is implemented through undo log.
Two-phase Commit protocol
The two-phase commit protocol is a type of atomic commitment protocol (abbr. ACP). It is a distributed algorithm that coordinates all the processes that participate in a distributed transaction on whether to commit or roll back the transaction. The two-phase commit in MySQL is as shown below.

Please note:
- When the redo log is done, the changes have already been persisted to disk (durability).
- When the binlog is done, the changes will be synchronized to the replica databases.
When crash happens at time point T1, the transaction will be rolled back and binlog has not been written, so the changes will not be synchronized to the replica databases.
When crash happens at time point T2, MySQL will judge whether the content in binlog is complete, if yes, commit the transaction, otherwise roll back the transaction.
Question: How to judge whether the content in binlog is complete?
Answer: When binlog is in ROW format, there will be a XID event in the last of a transaction. When binlog is in STATEMENT format, there will be a COMMIT event in the last of a transaction. The XID event or COMMIT Event can be used to judge whether the content is complete. Besides, there are also some other methods to judge whether the content is complete and correct.
Debezium with Binlog
Debezium is a tool which can parse MySQL binlog and generate the change events. It is very helpful for people to know what changes have happened in the database. Based on Debezium, It's hopeful to create historical database, which record the states of MySQL database at any time.
Time in Debezium
But there is a problem now. Debezium uses the time of the statement starts to execute, not the transaction commit time. This little difference makes knowing when the change is committed hard. Below is an example.
Step 1: Create a table and insert two rows;
Step 2: Execute an update SQL statement;
2
3
4
5
6
7
8
9
10
11
12
CREATE TABLE `persons` (
`PersonID` int(11) DEFAULT NULL,
`LastName` varchar(255) DEFAULT NULL,
`FirstName` varchar(255) DEFAULT NULL,
`Address` varchar(255) DEFAULT NULL,
`City` varchar(255) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=latin1;
-- insert two rows
insert into persons (PersonID) values (1);
insert into persons (PersonID) values (2);Step 3: Check Binlog content and change events generated by Debezium
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
Query OK, 0 rows affected (0.01 sec)
mysql> update persons set LastName = "" where PersonID = 1;
Query OK, 1 row affected (0.00 sec)
Rows matched: 1 Changed: 1 Warnings: 0
mysql> update persons set LastName = "1234" where PersonID = 2;
Query OK, 1 row affected (0.00 sec)
Rows matched: 1 Changed: 1 Warnings: 0
mysql> update persons set LastName = "abcd" where PersonID = 1;
Query OK, 1 row affected (0.00 sec)
Rows matched: 1 Changed: 1 Warnings: 0
mysql> commit;Summary:
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
/*!50718 SET TRANSACTION ISOLATION LEVEL READ COMMITTED*//*!*/;
# original_commit_timestamp=0 (1970-01-01 00:00:00.000000 UTC)
# immediate_commit_timestamp=0 (1970-01-01 00:00:00.000000 UTC)
/*!80001 SET @@session.original_commit_timestamp=0*//*!*/;
/*!80014 SET @@session.original_server_version=0*//*!*/;
/*!80014 SET @@session.immediate_server_version=0*//*!*/;
SET @@SESSION.GTID_NEXT= 'ANONYMOUS'/*!*/;
# at 1436
#220525 13:24:05 (This time is the same with first statement execute time in this transaction) server id 1060022966 end_log_pos 1516 CRC32 0xdd4ff59c Query thread_id=1389 exec_time=0 error_code=0
SET TIMESTAMP=1653485045/*!*/;
BEGIN
/*!*/;
# at 1516
#220525 13:24:05 server id 1060022966 end_log_pos 1586 CRC32 0x05ccbe51 Table_map: `jingtao_test`.`persons` mapped to number 226
# at 1586
#220525 13:24:05 (Debezium Time: 2022-5-25 13:24:5) server id 1060022966 end_log_pos 1638 CRC32 0xe68dc86e Update_rows: table id 226 flags: STMT_END_F
### UPDATE `jingtao_test`.`persons`
### WHERE
### @1=1 /* INT meta=0 nullable=1 is_null=0 */
### @2='TA-1' /* VARSTRING(255) meta=255 nullable=1 is_null=0 */
### @3=NULL /* VARSTRING(255) meta=255 nullable=1 is_null=1 */
### @4=NULL /* VARSTRING(255) meta=255 nullable=1 is_null=1 */
### @5=NULL /* VARSTRING(255) meta=255 nullable=1 is_null=1 */
### SET
### @1=1 /* INT meta=0 nullable=1 is_null=0 */
### @2='' /* VARSTRING(255) meta=255 nullable=1 is_null=0 */
### @3=NULL /* VARSTRING(255) meta=255 nullable=1 is_null=1 */
### @4=NULL /* VARSTRING(255) meta=255 nullable=1 is_null=1 */
### @5=NULL /* VARSTRING(255) meta=255 nullable=1 is_null=1 */
# at 1638
#220525 13:24:33 server id 1060022966 end_log_pos 1708 CRC32 0x614e827e Table_map: `jingtao_test`.`persons` mapped to number 226
# at 1708
#220525 13:24:33 (Debezium Time 2022-5-25 13:24:33) server id 1060022966 end_log_pos 1760 CRC32 0x9b6c6fd6 Update_rows: table id 226 flags: STMT_END_F
### UPDATE `jingtao_test`.`persons`
### WHERE
### @1=2 /* INT meta=0 nullable=1 is_null=0 */
### @2='' /* VARSTRING(255) meta=255 nullable=1 is_null=0 */
### @3=NULL /* VARSTRING(255) meta=255 nullable=1 is_null=1 */
### @4=NULL /* VARSTRING(255) meta=255 nullable=1 is_null=1 */
### @5=NULL /* VARSTRING(255) meta=255 nullable=1 is_null=1 */
### SET
### @1=2 /* INT meta=0 nullable=1 is_null=0 */
### @2='1234' /* VARSTRING(255) meta=255 nullable=1 is_null=0 */
### @3=NULL /* VARSTRING(255) meta=255 nullable=1 is_null=1 */
### @4=NULL /* VARSTRING(255) meta=255 nullable=1 is_null=1 */
### @5=NULL /* VARSTRING(255) meta=255 nullable=1 is_null=1 */
# at 1760
#220525 13:27:26 server id 1060022966 end_log_pos 1830 CRC32 0xa375ebe5 Table_map: `jingtao_test`.`persons` mapped to number 226
# at 1830
#220525 13:27:26 (Debezium Time: 2022-5-25 13:27:26) server id 1060022966 end_log_pos 1890 CRC32 0x442acf49 Update_rows: table id 226 flags: STMT_END_F
### UPDATE `jingtao_test`.`persons`
### WHERE
### @1=1 /* INT meta=0 nullable=1 is_null=0 */
### @2='' /* VARSTRING(255) meta=255 nullable=1 is_null=0 */
### @3=NULL /* VARSTRING(255) meta=255 nullable=1 is_null=1 */
### @4=NULL /* VARSTRING(255) meta=255 nullable=1 is_null=1 */
### @5=NULL /* VARSTRING(255) meta=255 nullable=1 is_null=1 */
### SET
### @1=1 /* INT meta=0 nullable=1 is_null=0 */
### @2='abcd' /* VARSTRING(255) meta=255 nullable=1 is_null=0 */
### @3=NULL /* VARSTRING(255) meta=255 nullable=1 is_null=1 */
### @4=NULL /* VARSTRING(255) meta=255 nullable=1 is_null=1 */
### @5=NULL /* VARSTRING(255) meta=255 nullable=1 is_null=1 */
# at 1890
#220525 13:29:23 server id 1060022966 end_log_pos 1921 CRC32 0x8236f09a Xid = 22148
COMMIT/*!*/;Important: This is an example of
- The timestamp of the transaction starts is the same with the transaction commit time.
begin;The timestamp ofbeginis the same with first update statement start executing time.updateThe timestamp of this type statements are when the statements start executing.commitThe timestamp ofcommitis the time when executingcommitcommand.- The change events generated by Debezium only include the time of statements start executing, but not the transaction commit time which is very important for when other transactions can see the changes.
Refer Link:
- GitHub PR DBZ-5170 Mysql Commit Timestamp #3555
- DBZ-5170 Mysql Commit Timestamp #83
- Red Hat MySQL Commit Timestamp
Transaction ID in Debezium
There is a simple test, as the below step:
GTID is disabled in MySQL.
- Start capturing changes with
schema_onlymode. - Make changes in MySQL
- Start dumping snapshot with
initial_onlymode andminimallocking mode. - Make changes again.
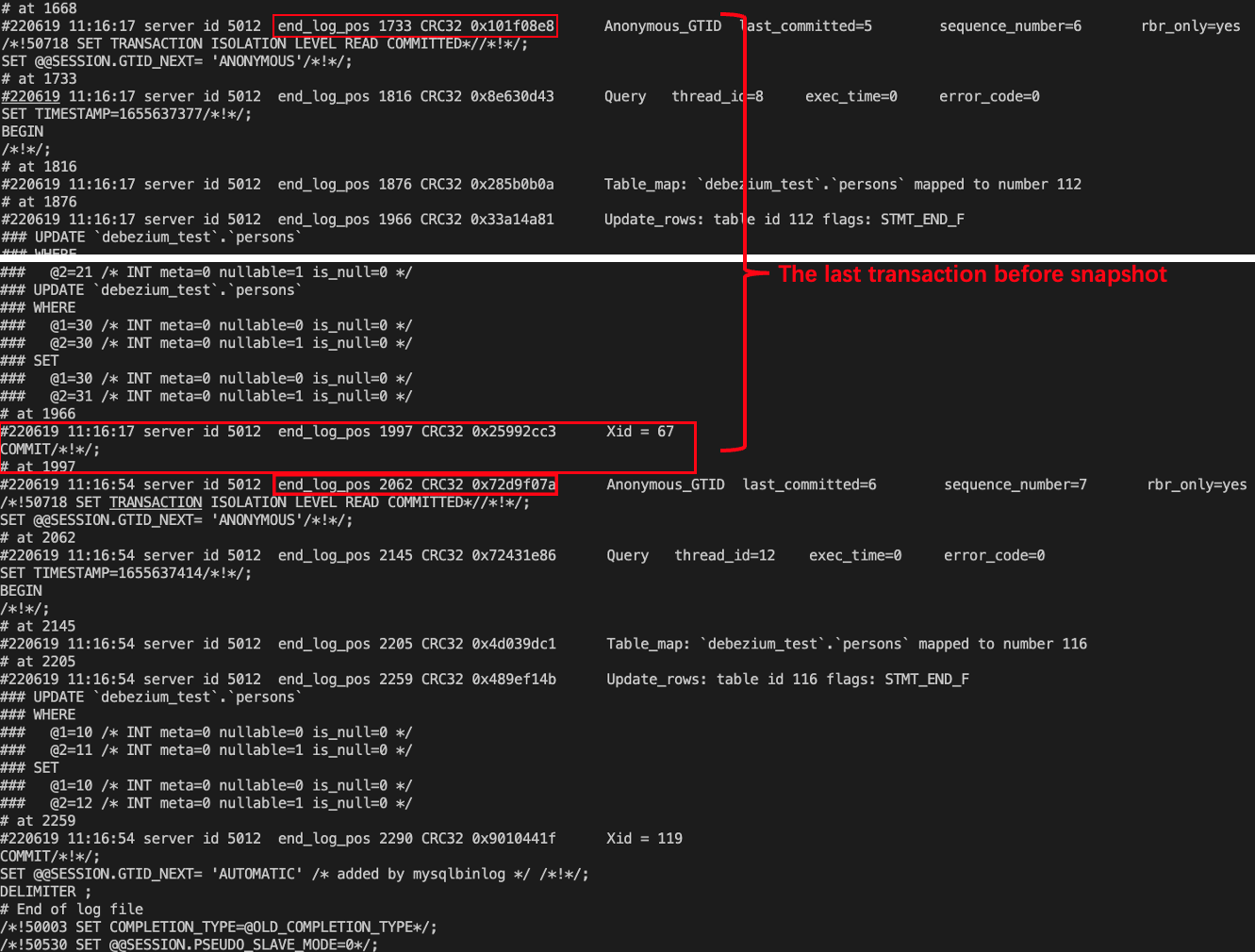
Result:
- The last transaction id before snapshot is
"file=mysql-bin.000003,pos=1733" - The binlog status recorded by dump job is
"file": "mysql-bin.000003", "pos": 1997 - The first transaction id after snapshot is
"file=mysql-bin.000003,pos=2062"
Content in Binlog is as shown below:
SQL Commands
SQL commands are divided into four subgroups, DDL, DML, DCL, and TCL.
DDL
Data Definition Language, including:
- CREATE
- ALTER
- DROP
- TRUNCATE
- COMMENT
- RENAME
DML
Data Manipulation Language, including:
- SELECT
- INSERT
- UPDATE
- DELETE
- MERGE
- CALL
- EXPLAIN PLAN
- LOCK TABLE
DCL
Data Control Language, including:
- GRANT
- REVOKE
TCL
Transaction Control Language, including:
- COMMIT
- ROLLBACK
- SAVEPOINT
- SET TRANSACTION
Refer
- MySQL 5.7 Reference Manual --5.4.4 The Binary Log
- MySQL 5.7 Reference Manual --5.4.4.1 Binary Logging Formats
- MySQL 5.7 Reference Manual --14.7.1 InnoDB Locking
- MySQL 5.7 Reference Manual --14.7.2.3 Consistent Nonlocking Reads
- MySQL 5.7 Reference Manual --15.7.2.1 Transaction Isolation Levels
- MySQL 5.7 Reference Manual --16.1.3 Replication with Global Transaction Identifiers
- Wikipedia --Two-phase Commit Protocol
- Debezium 1.8 Official Doc --Debezium Connector for MySQL
- Blog --You Must Understand the Three Major MySQL Logs -Binlog, Redo Log and Undo log. Posted on Juejin
- Jingtao Blog --MySQL Knowledge Points Summary