Raft简介
Raft算法正常工作时的成员组成是1个Leader和多个Follower,将一致性问题拆解成3个部分,简化整体思想。
- Leader 选举
- 日志复制
- 安全safety措施
Raft算法的核心流程可以归纳如下,如下图所示:
- 选出leader,由leader负责接收客户端的更新、删除请求
- 将日志复制到其他的follower节点,通过safty准则保证数据一致性
- leader故障,follower会重新选举出新的leader
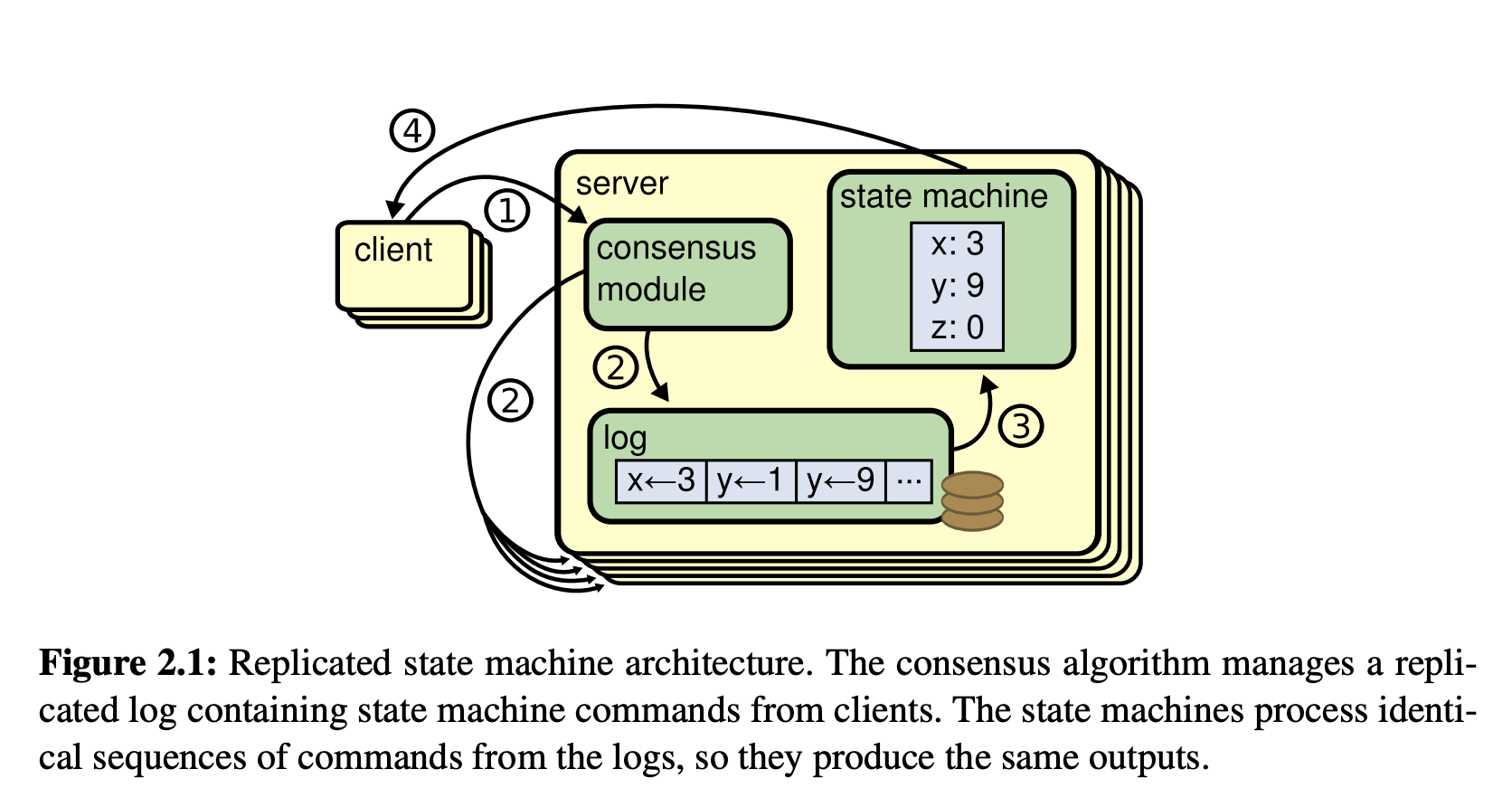
基本概念
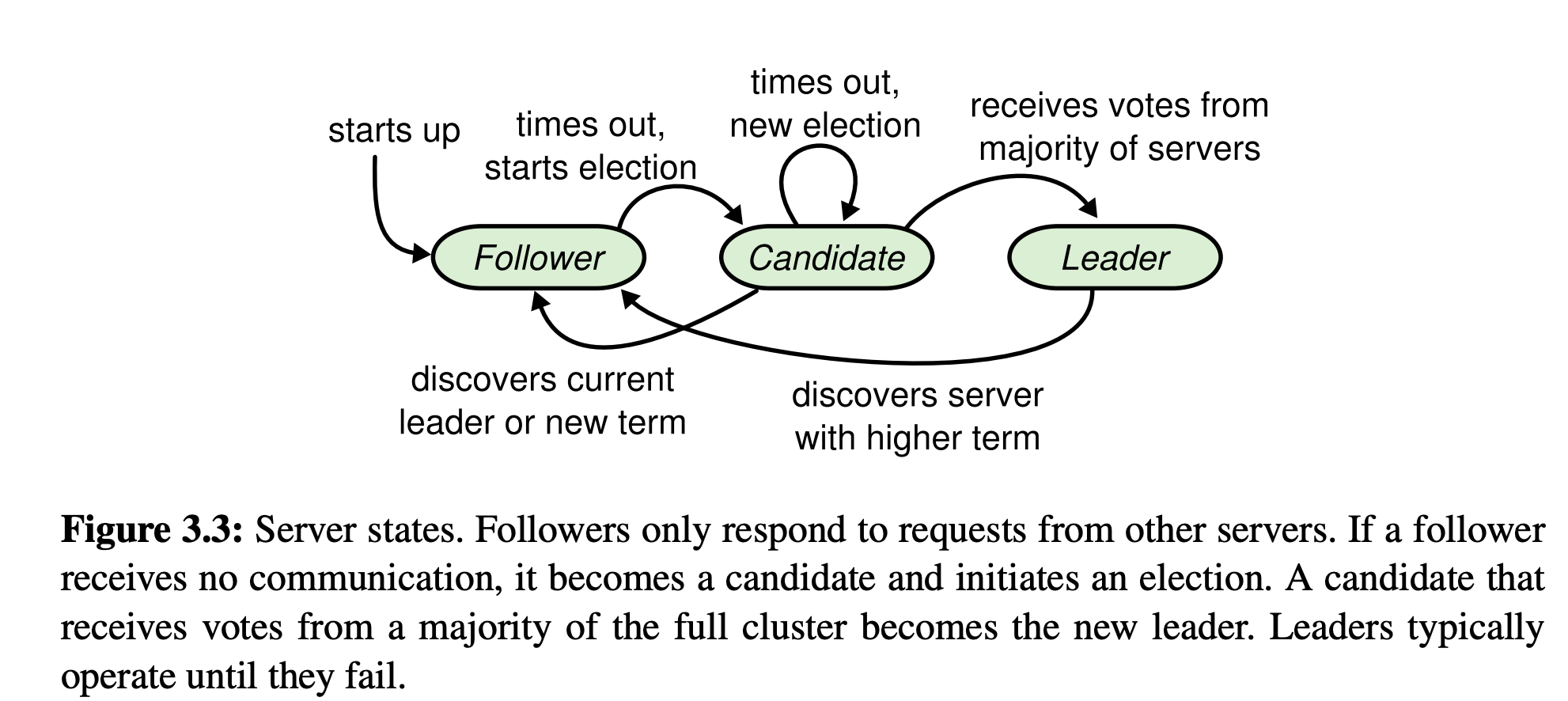
Leader的选举过程就体现在节点的状态变化过程中,如下图。节点身份的状态有Follower、Candidate、Leader。
- 在起始状态节点默认是Follower
- 在起始状态或者与leader通信超时,节点从Follower => Candidate
- 当Candidate赢得选举,Candidate => Leader
- 当Candidate选举超时,Candidate => Candidate
- 当Candidate收到更高任期的Leader通信请求,Candidate => Follower
- 当Leader收到更高任期的Leader通信请求,Leader => Follower
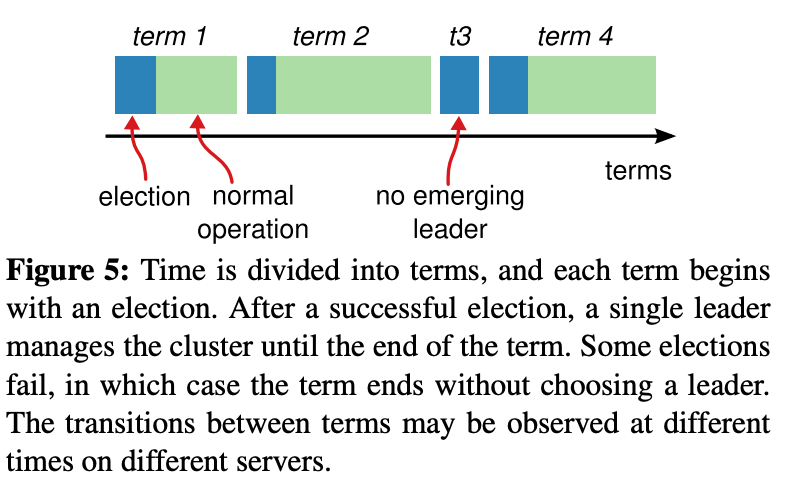
关于任期的解释,在Raft协议中,将时间分成了一些任意长度的时间片,称为term,term使用连续递增的编号的进行识别,如下图所示。
每一个term都从新的选举开始,candidate们会努力争取称为leader。一旦获胜,它就会在剩余的term时间内保持leader状态,在某些情况下(如term3)选票可能被多个candidate瓜分,形不成多数派,因此term可能直至结束都没有leader,下一个term很快就会到来重新发起选举。
term也起到了系统中逻辑时钟的作用,每一个server都存储了当前term编号,在server之间进行交流的时候就会带有该编号,如果一个server的编号小于另一个的,那么它会将自己的编号更新为较大的那一个;如果leader或者candidate发现自己的编号不是最新的了,就会自动转变为follower;如果接收到的请求的term编号小于自己的当前term将会拒绝执行。
Leader选举
raft通过心跳机制发起leader选举,Follower在Candidate和Leader的心跳信号下维持自己的Flower状态。若超时没有收到上述信号,Follower会增加当前term编号,转变成Candidate状态,首先会给自己投一票,然后并行向其他所有节点发出通票请求。然后将会发生三种情况:
- 赢得半数投票成为Leader,进入term的normal operation段
- 收到其他的leader心跳,此时会比较term的编号,如果比自己小,则说明对方是过期的leader,继续保持candidate状态;如果不比自己小,承认对方身份,转化成follower状态
- 选票被瓜分,选举失败,在规定的时间内没有选举结果,candidate会重新发起选举过程,为了防止下次仍被瓜分选票,candidate会随机等待一段时间再发起选举流程,错开请求。
日志复制流程
leader会串行记录客户端的命令到日志中,每条命令都包含term编号和顺序索引;然后leader会将日志并行发送给其他所有节点,当大多数节点复制成功后,leader会提交命令并反馈给客户端结果。在上述过程中raft保证已经提交的命令最终会被其他节点执行,但不是在当前任期内就会被执行。
在集群经历过几次故障之后,可能会发生如下的情况,leader的日志没有被完全复制,leader中的日志也是不完整的,就会表现出看起来十分混乱的情况,甚至有些节点既有leader没有的日志,leader也有他没有的日志的情况。
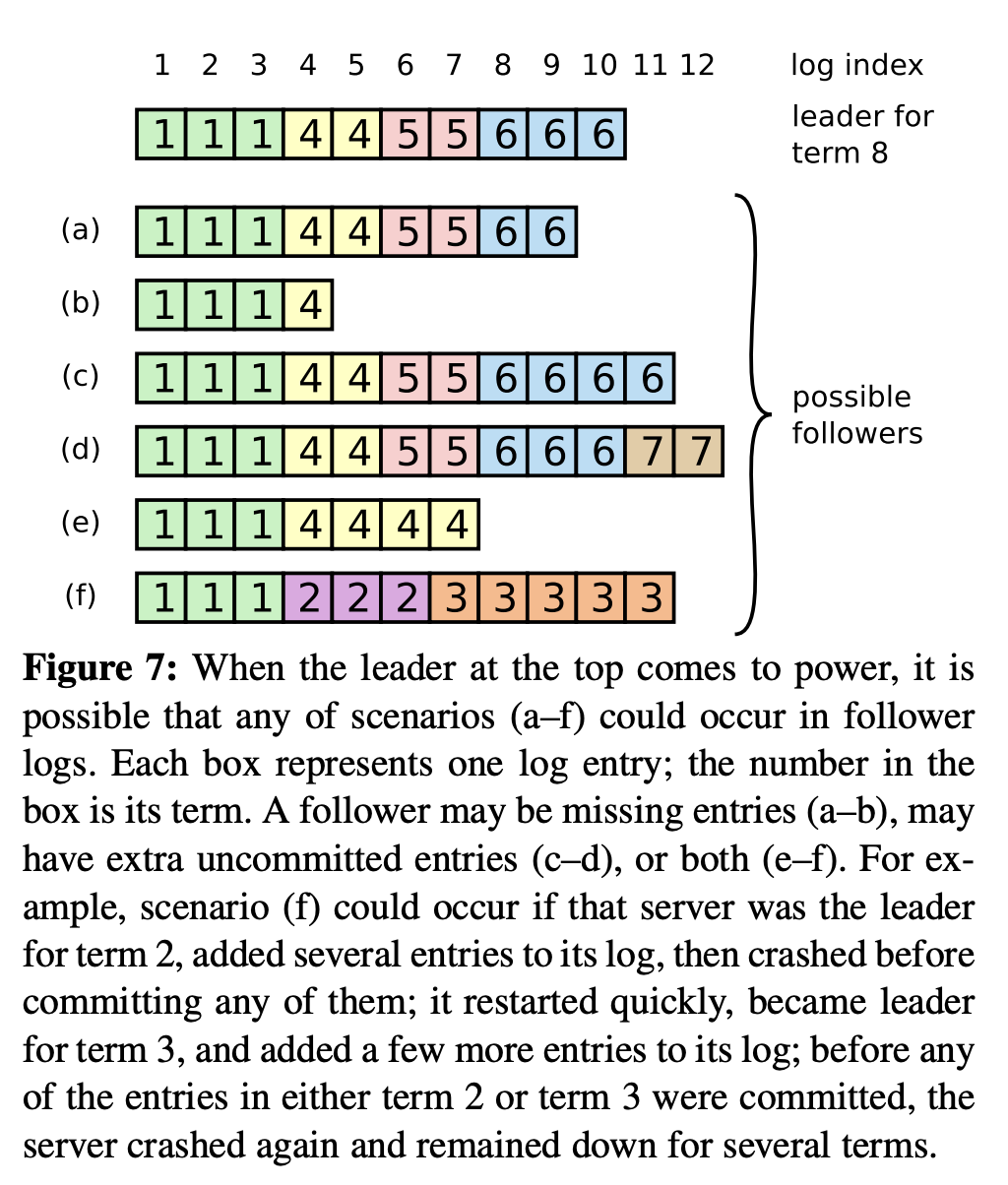
其中leader缺失日志是致命的问题,raft通过在选举过程中添加限制条件,确保leader包含之前term已经提交过的所有命令。限制条件体现在投票的时候follower不会给日志编号比自己小的candidate投票。
还可能会出现另外一个问题, 如果命令已经被复制到了大部分节点上,但是还没来的及提交就崩溃了,这样后来的leader应该完成之前term未完成的提交. Raft通过让leader统计当前term内还未提交的命令已经被复制的数量是否半数以上, 然后进行提交.
日志压缩
添加
参考资料
《docker 容器与容器云》