Go Scheduler
基本概念
OS Thread(M)
该文中没有详细的介绍,我理解的是操作系统的内核线程。
Logical Processor(P)
当Go程序开始执行时,会对应主机的每个虚拟核心有一个P,例如在一台四核心八线程的电脑上,会对应有4个P。 可以通过下面的程序查看Logical Processor的数量。
1 | package main |
每一个P都被分配到了操作系统的线程(OS Thread(M)M表示的是机器的意思(本人的理解此处想表达的是内核线程))上,这个线程依旧被操作系统管理,由操作系统将线程放置到内核上去执行。因此在四核心八线程的电脑上,一个Go程序有8个可用线程来执行相关的工作,每一个都和一个P绑定在一起。
Goroutine(G)
每一个Go程序都有一个初始化的Goroutine,这是Go程序执行的路径。Goroutine的本质是一个协程(Coroutine),但是在Go语言中,将首字母C换成了G,于是诞生了Goroutine。可以将Goroutine当作是一个应用程序级别的线程(application-level threads),类比于OS thread在CPU核心上进行上下文切换,Goroutine在OS thread(M)上进行上下文切换。
调度模型
Run Queue
在Go中有两种不同的运行队列(Run Queue),一种是全局运行队列(Global Run Queue),另一种是本地运行队列(Local Run Queue)。每一个P都有一个LRQ,管理着该P上负责执行的Goroutines,这些Goroutines在该P对应的M上面进行上下文切换,轮流执行。GRQ上管理的是还没有分配给P的那些Goroutines,有一个进程专门将Goroutines分配给一个P。
Cooperating Scheduler
抢占式调度和协作式调度:
操作系统的调度是抢占式的,这就以为着我们不能预测在某个确切的时间点,将会发生什么。内核将会进行调度,并且是非确定性的。
协作式调度大多是在用户空间层(内核层之上)因为没有内核层强大的调度权利,因此协作式调度往往需要更加良好的设计。
Go Scheduler就是一个协作式调度,但他表现的却像是一个抢占式调度程序,这是因为Go Scheduler的决策权并不掌握在开发人员手中,而是在Go运行时决定的。
Goroutine States
Goroutine也拥有三种运行状态:
- Waiting:不可被执行,等待系统调用或者同步调用(例如原子或者互斥操作)
- Runnable:可被执行,但需要等待M
- Executing:正在M上执行
Context Switch
因为Go Schedule是协作式调度,因此需要定义明确的用户空间事件,该事件发生在代码的安全点处,来进行安全的上下文切换。这些安全点在函数调用中体现出来,在Go1.11或者更早的版本,若代码中包含没有函数调用的紧密循环体(本人理解的是循环非常多次),则会对调度程序和垃圾回收产生明显的延迟。
在Go的1.12及以后的版本中,Go Scheduler采用了非协作抢占式技术,来允许在没有函数调用的紧密循环体中进行抢占。可参考
下面四种情况,将会给Go Scheduler进行调度的机会
使用关键字
go在创建一个新的Goroutine的时候,将会给Go Scheduler上下文切换的机会
垃圾回收(GC)
在垃圾回收的时候,会有专门的垃圾回收Goroutine运行在M上,这个时候Scheduler会利用GC得到情报,制定调度策略,例如使用不需要访问heap的Goroutine替换需要访问heap的Goroutine。
系统调用(System Call)
当执行系统调用时,Goroutine将会阻塞M,有时候Scheduler有能力将其换下,有时候需要一个新的M来执行队列中的Goroutine(不太理解),具体将会在下文介绍。
同步与编排(Synchronization and Orchestration)
如果一个原子操作(automic)、互斥操作(mutex)或者一个队列操作(channel)会造成Goroutine阻塞,Scheduler有能力将其换下。
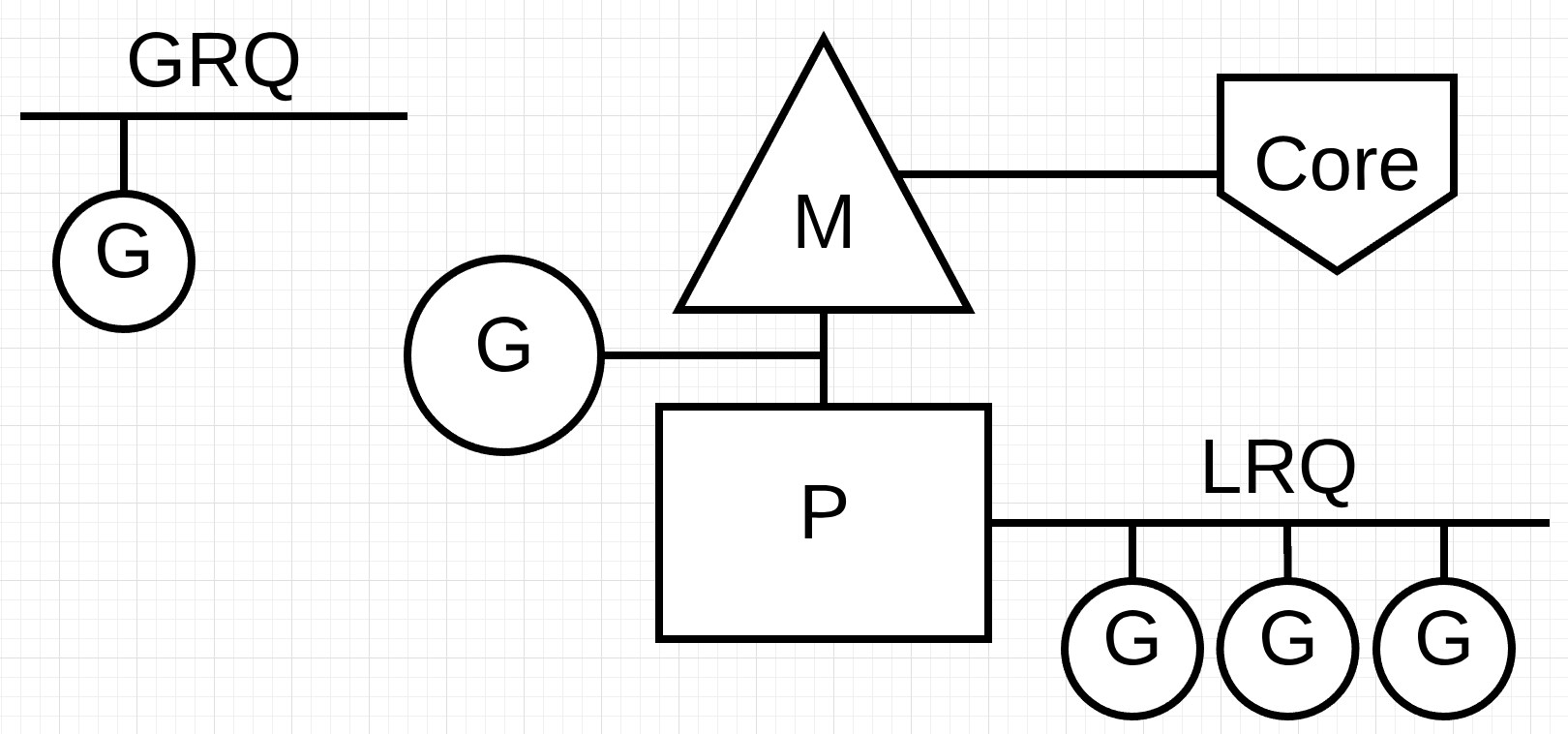
Asynchronous System Calls
当操作系统又能力进行异步系统调用,例如network poller(在Linux中表现为epoll),Scheduler将会采用更加高效的调度策略来提升调度效率。
例如,G1正在执行,掉用了NetPoller的异步系统调用,那么G1将会给挂到netPoller的阻塞队列中去,Go Scheduler将会安排LRQ中的G进行执行。当G1的异步系统调用执行完成,G1将会从NetPoller中移回到LRQ中。
Synchronous System Calls
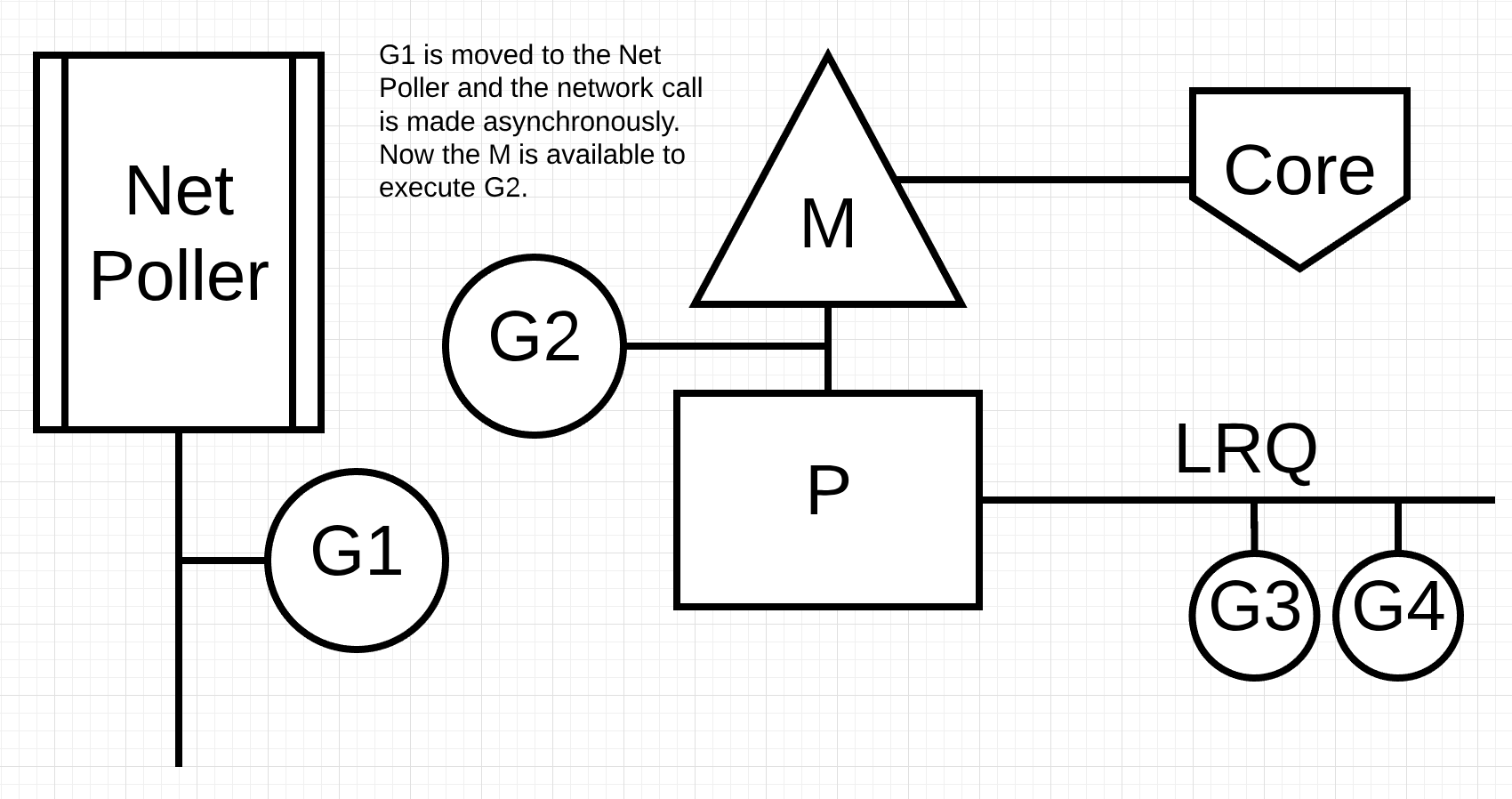
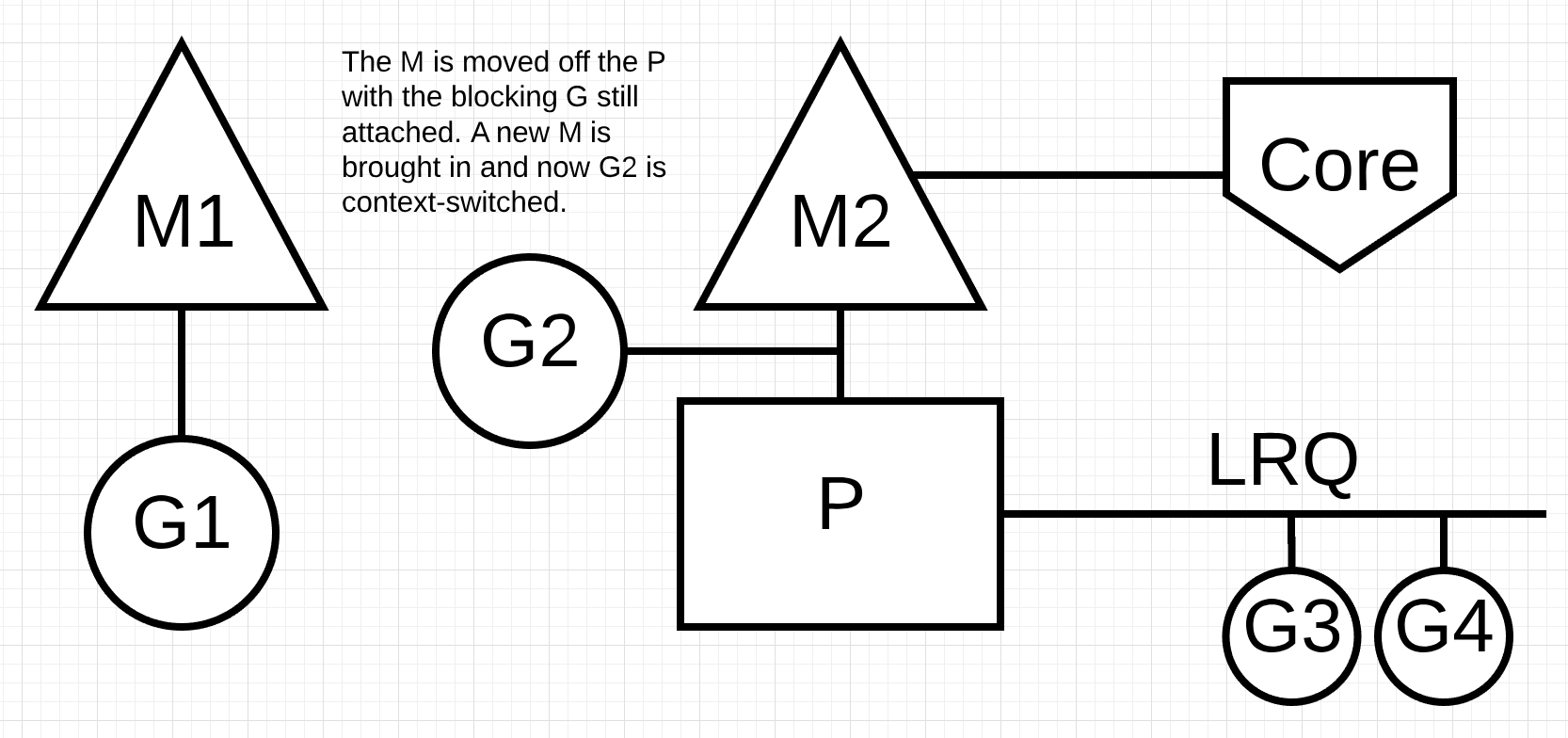
同步系统调用不能像异步系统调用那样不去阻塞M的执行,因此Scheduler采用了一种有趣的方式进行执行。
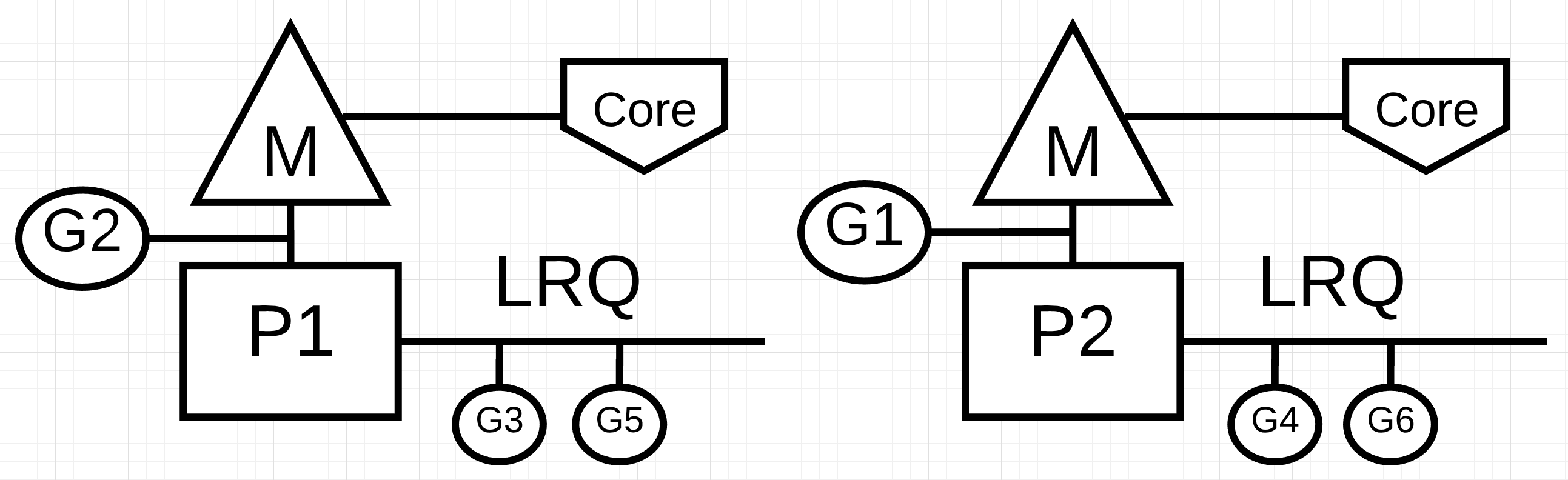
例如,G1正在执行,调用了同步系统调用,此时Scheduler会将P1分配到M1换掉,换成一个新的M2,M1上继续执行折被阻塞的G1,等G1的系统调用结束,他将会回到P1的LRQ中。M1也将会被留着下次出现这种情况时进行替换。如下图:
Work Stealing
工作窃取有助于在所有的P上平衡Goroutines,从而更好的分配工作并高效的完成工作。例如下面的情况,P1没有可以执行的Goroutines,但所有处于Runnable的G都在P2的LRQ和GRQ上。这个时候P1需要偷一些工作。
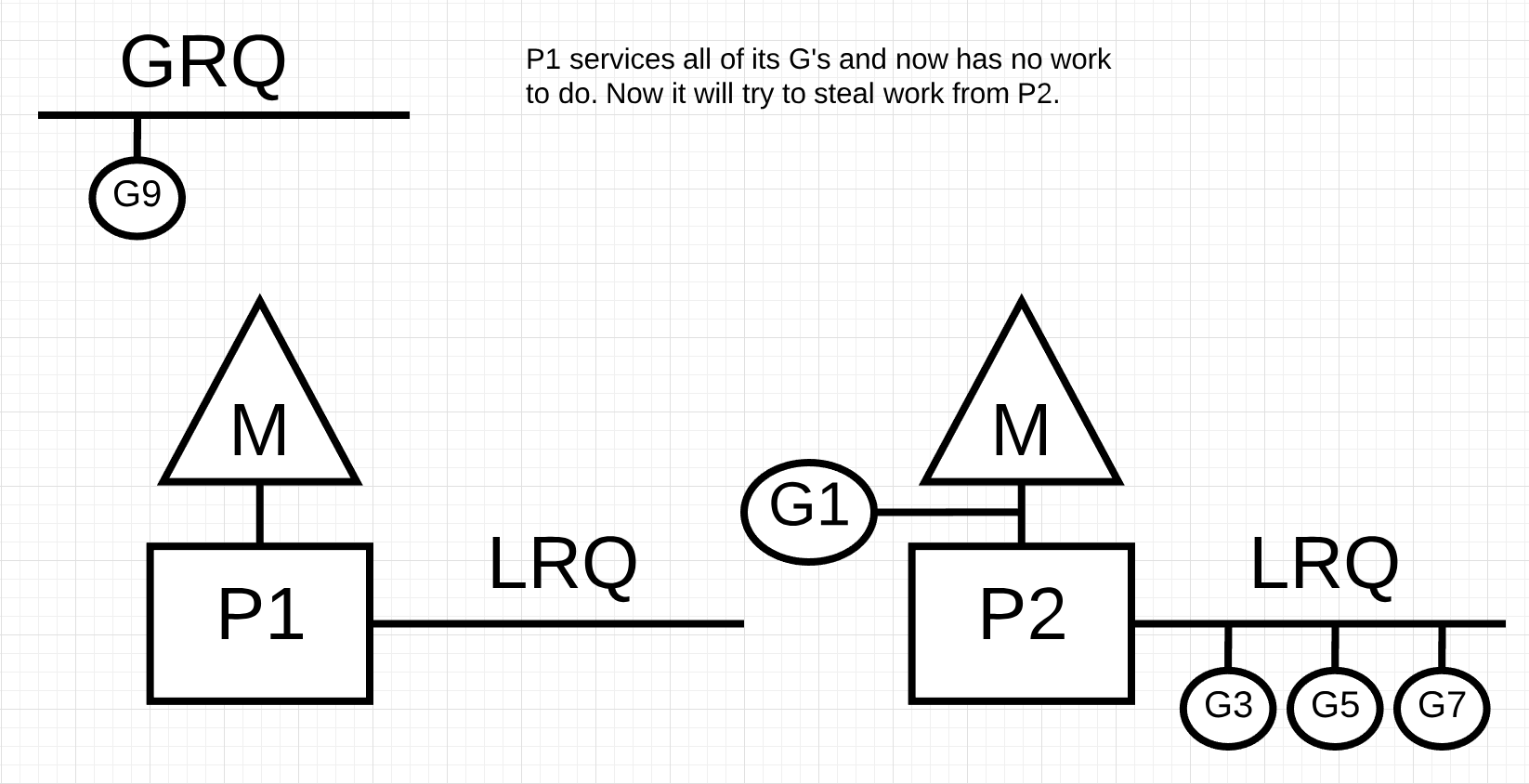
偷取工作的原则如下:
1 | runtime.schedule() { |
例子
将通过一个简单的例子,解释Go Scheduler设计的好处
例如下面的例子使用C语言编写的两个线程之间的交互,情况如下:
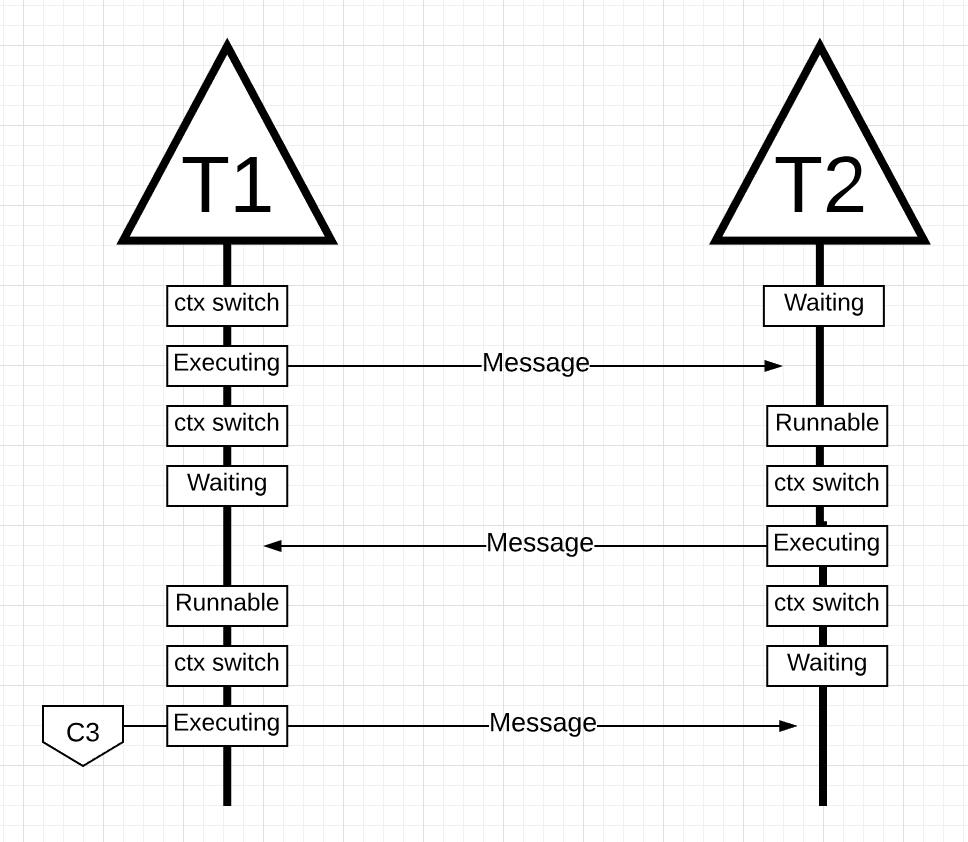
两个线程在此过程中发生了多次上下文的切换,这些切换都需要时间。并且切换是有可能发生在多个核心之间,还可能因为没有告诉缓存没有命中而造成额外的时间开销。
上述例子如果使用Goroutine去执行,情况如下:
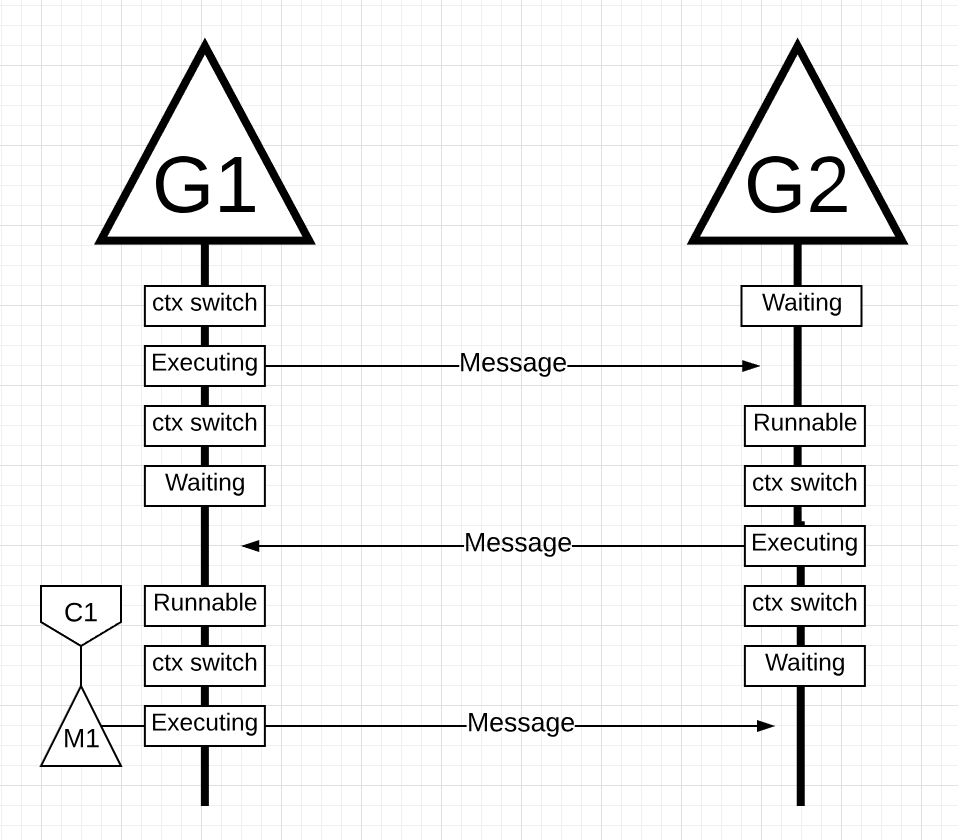
整个流程看起来和使用Thread貌似没有什么不同,但是在使用Goroutine的情况下,G1和G2使用的都是相同的OS Thread(M)和Core,从操作系统的角度,执行运算的线程从没有进入等待状态;并且在线程上下文切换时候丢失的指令,在使用Goroutine的时候没有丢失(本人的理解是OS Thread没有进行实质上的上下文切换,所以不存在因为上下文切换耽误的指令的执行)。
从本质上讲,在操作系统层面,Go将I/O blocking转换成了CPU范畴的工作,并且由于都是在应用程序级别的上下文切换相比于线程级别的切换将会更快(线程级别的切换将会平均耗费12k条指令,而应用程序级别的切换平均只需要2.4k条指令)。此外还可以提供高速缓存的命中效率和NUMA。这也是Go不需要多于虚拟内核的线程数的原因。在Go的调度过程中,会尝试使用更少的线程,并且在每个线程上执行尽可能多的工作,有助于减少操作系统和硬件的负载。
总结
The Go scheduler is really amazing in how the design takes into account the intricacies of how the OS and the hardware work. The ability to turn IO/Blocking work into CPU-bound work at the OS level is where we get a big win in leveraging more CPU capacity over time. This is why you don’t need more OS Threads than you have virtual cores. You can reasonably expect to get all of your work done (CPU and IO/Blocking bound) with just one OS Thread per virtual core. Doing so is possible for networking apps and other apps that don’t need system calls that block OS Threads.
As a developer, you still need to understand what your app is doing in terms of the kinds of work you are processing. You can’t create an unlimited number of Goroutines and expect amazing performance. Less is always more, but with the understanding of these Go-scheduler semantics, you can make better engineering decisions. In the next post, I will explore this idea of leveraging concurrency in conservative ways to gain better performance while still balancing the amount of complexity you may need to add to the code.
Concurrency
在遇到一个新问题的时候,并不需要关注并发是不是有好处的,而是要先通过串行的方式完成工作,并经过易读性和技术审查之后,再去考虑并发是不是有好处的。
该文章提供了:
- 对于是否应该使用并发的一个语义指导
- 不同类型的工作负载是如何改变语义的,从而改变工作的决策
注意并发和并行并不相同,在下面的例子中,所有的G都是并发的,但仅有G1和G2是并行的。
有时候,在没有并发的情况下利用并行,会减慢吞吐速度。有时候将并发和并行结合起来也不会实现更大的性能提升。
Workloads
程序会有两大类工作负载:
- CPU-Bound:永远不会造成Goroutines自然地进入和退出等待状态的工作负载,例如计算Pi的第n位
- IO-Bound:这种工作负载会自然地造成Goroutine自然地进入waiting状态的负载,例如执行网络操作、发生系统调用或者等待某个事件。需要读取文件的Goroutine、或者同步事件(互斥、原子)导致Goroutine需要等待的,都算这个范畴
CPU-Bound类型的程序,需要利用并行来提高并发能力。在单个线程的机器上处理多个Goroutines并不会高效,因为上下文切换造成的延迟,在上下文切换期间会发生Stop The World的事件,在这期间没有执行任何有效的任务。
IO-Bound类型的程序,并不需要利用并行来提高并发能力,在单线程的机器上处理多个Goroutine将会是高效的。因为G会自然的进入waiting状态,而不是被强制打断。这就不会发生Stop The Wolrd事件,G自然的进入waiting状态,切换其他G进行运行,将更有效的利用线程。
针对IO-Bound类型的任务,太少的G将会造成过多的Idle Time,太多的G会造成过多的上下文切换的时间。
Demo
Adding Numbers
1 | 36 func add(numbers []int) int { |
针对上面的求和函数,我们可以利用并行来提高执行速度,将numbers拆分成多个小数组,分别计算和,再将每个小数组和的结果再相加,同样是最终的答案。
按照上述逻辑,改进之后的版本,可以通过指定切分的数量,充分利用CPU的核心,进行计算。
1 | 44 func addConcurrent(goroutines int, numbers []int) int { |
完整代码,在此。
测试代码如下
1 | func BenchmarkSequential(b *testing.B) { |
1 | GOGC=off go test -cpu 1 -run none -bench . -benchtime 3s |
在一个核心的情况下,串行计算方式要比并发的方式快10%
在八个核心的情况下,并发计算方式要比串行快40%
Sorting
完整代码,在此。