Linux基础
Namespace
proc/[pid]/ns目录下存放了不同进程的namespace号,在bash中查看当前进程不同资源的所属的NS。注意下面是通过link的方式指向不同的NS,当一个NS下的所有进程都退出,NS依旧会存在。
1 | (base) ➜ ~ ls -l /proc/$$/ns |
不同NS限制的不同资源如下表所示
| NS 名称 | 隔离内容 |
|---|---|
| NS(mnt) | 隔离文件系统的挂载点 |
| UTS | 隔离HostName 和 DomainName |
| IPC | 隔离进程间的通信 |
| PID | 隔离进程 |
| NET | 隔离网络,包括: 网络设备、IPV4和IPV6协议栈、IP路由表、防火墙、 /proc/net目录、/sys/class/net目录、socket |
| USER | 隔离用户和用户组 |
UTS IPC PID
创建新的UTS、IPC、PID,实现隔离能力
1 | /** |
运行结果
1 | root@jingtao-HP-Z440-Workstation:/home/jingtao/repos/algorithm-exercises# ipcmk -Q |
可以通过unshare()允许用户在原有进程中建立命名空间的隔离;setns()加入已经存在的命名空间。除了PID Namespace,原先的调用者都会立马创建新的或者进入指定的Namespace空间;而PID Namespace只会影响后续创建的子进程的命名空间,对调用者进程不产生影响。
Mount Namespace
Mount namespace 通过隔离文件系统挂载点对隔离文件系统提供支持。因为是第一个Namespace,所以标识地位比较特殊名为CLONE_NEWNS。
当进程创建mount namespace的时候,会把当前的文件结构复制给新的Namespace,新Namespace中所有的mount操作,只影响自身的文件系统,对外界不会产生任何影响。这种做法十分严格的实现了隔离。
2006年引入了挂载传播(mount propagation),挂载传播定义了挂载对象之间的关系:
- 共享关系,挂载事件会在两个NS中传播
- 从属关系,只可以从主影响到属,反之不会
挂载状态因此分为一下几种
- 共享挂载:传播事件的挂载对象(--make-shared)
- 从属挂载:接受事件的挂载对象(--make-slave)
- 共享/从属挂载:即可传播也可接收的挂载对象
- 私有挂载:不传播也不接收的挂载对象(默认挂载状态--make-private)
- 不可绑定挂载:创建mount NS的时候,该挂载对象不可被复制(--make-unbindable)
Network Namespace
Network namespace提供了网络资源的隔离,包括网络设备、IPV4和IPV6协议栈、IP路由表、防火墙、/proc/net目录、/sys/class/net目录、socket等。
一个物理设备只能存在一个Network NS下,NS退出时,物理设备都会回到root Namespace而不是创建该进程的父进程所在的Network Namespace
Linux 虚拟网络设备
具体工作原理可以参考《Linux 上的基础网络设备详解》
bridge
Linux网桥设备,是Linux提供的一种虚拟网络设备之一,和物理交换机类似,可以工作在二层也可以工作在三层。可以用iproute2工具包或brctl命令对Linux bridge进行管理
veth
virtual Ethernet,Linux提供的另一种虚拟网络设备,虚拟网卡接口。它总是成对出现,要创建就创建一个pair。一个Pair中的veth就像一个网络线缆的两个端点,数据从一个端点进入,必然从另外一个端点流出。每个veth都可以被赋予IP地址,并参与三层网络路由过程。
实战
基于Network Namespace进行如下的网络环境模拟,分如下步骤进行
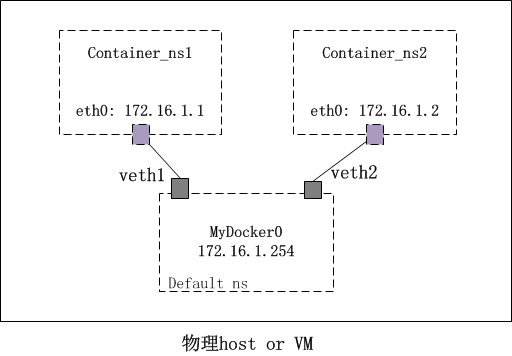
创建容器所在的namespace
1 | root@jingtao-HP-Z440-Workstation:~# ip netns add Container_ns1 |
新创建的Network Namespace Container_ns1和Container_ns2只有一个loopback口,并且路由表为空
创建网桥
1 | # 创建网桥 |
创建veth连线
1 | root@jingtao-HP-Z440-Workstation:~# ip link add veth1 type veth peer name veth1p |
连通性测试
1 | # 连通性测试 |
端口映射模拟
端口映射模拟基于userland proxy例子。
docker默认实现端口映射的方式是docker engine 的docker proxy实现的,其会为每个expose端口的容器启动一个proxy实例来做端口流量转发。通过查找进程可以发现这些进程
1 | root@jingtao-HP-Z440-Workstation:~# ps -ef | grep docker-proxy |
下面来进行模拟
在Contaner_ns1 NS下启动一个web服务
web服务的代码如下
1
2
3
4
5
6
7
8
9//testfileserver.go
package main
import "net/http"
func main() {
http.ListenAndServe(":8080", http.FileServer(http.Dir(".")))
}启动服务,并进行测试
1
2
3
4
5
6
7
8
9
10
11# 编译
root@jingtao-HP-Z440-Workstation:~# go build testfileserver.go
# 启动服务
root@jingtao-HP-Z440-Workstation:~# ip netns exec Container_ns1 ./testfileserver &
[1] 317124
# 在Container_ns1下面已经可以看到被占用的8080端口
root@jingtao-HP-Z440-Workstation:~# ip netns exec Container_ns1 lsof -i tcp:8080
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
testfiles 317124 root 3u IPv4 8355872 0t0 TCP *:http-alt (LISTEN)
# 在默认命名空间下仍看不到8080端口被占用
root@jingtao-HP-Z440-Workstation:~# lsof -i tcp:8080设置转发代理
转发逻辑代码如下
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60//proxy.go
package main
import (
"flag"
"fmt"
"io"
"log"
"net"
)
var (
host string
port string
container string
containerport string
)
func main() {
flag.StringVar(&host, "host", "0.0.0.0", "host addr")
flag.StringVar(&port, "port", "", "host port")
flag.StringVar(&container, "container", "", "container addr")
flag.StringVar(&containerport, "containerport", "8080", "container port")
flag.Parse()
fmt.Printf("%s\n%s\n%s\n%s", host, port, container, containerport)
ln, err := net.Listen("tcp", host+":"+port)
if err != nil {
// handle error
log.Println("listen error:", err)
return
}
log.Println("listen ok")
for {
conn, err := ln.Accept()
if err != nil {
// handle error
log.Println("accept error:", err)
continue
}
log.Println("accept conn", conn)
go handleConnection(conn)
}
}
func handleConnection(conn net.Conn) {
cli, err := net.Dial("tcp", container+":"+containerport)
if err != nil {
log.Println("dial error:", err)
return
}
log.Println("dial ", container+":"+containerport, " ok")
go io.Copy(conn, cli)
_, err = io.Copy(cli, conn)
fmt.Println("communication over: error:", err)
}启动服务,并进行测试
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25root@jingtao-HP-Z440-Workstation:~# go build proxy.go
root@jingtao-HP-Z440-Workstation:~# ./proxy -host 0.0.0.0 -port 9090 -container 172.16.1.1 -containerport 8080
0.0.0.0
9090
172.16.1.1
80802021/08/30 20:09:06 listen ok
^C
root@jingtao-HP-Z440-Workstation:~# ./proxy -host 0.0.0.0 -port 9090 -container 172.16.1.1 -containerport 8080 &
[2] 318308
root@jingtao-HP-Z440-Workstation:~# 0.0.0.0
9090
172.16.1.1
80802021/08/30 20:09:12 listen ok
root@jingtao-HP-Z440-Workstation:~# curl 127.0.0.1:9090
2021/08/30 20:09:26 accept conn &{{0xc0000c6080}}
2021/08/30 20:09:26 dial 172.16.1.1:8080 ok
<pre>
...
<a href="proxy">proxy</a>
<a href="proxy.go">proxy.go</a>
<a href="testfileserver">testfileserver</a>
<a href="testfileserver.go">testfileserver.go</a>
</pre>
communication over: error: <nil>
通过这种代理转发的方式的代价十分高昂,之后可以通过iptables的方式进行目的地址转发,参考Docker架构概览中的Network部分。
User Namespace
通过User Namespace,一个普通用户进程在新的user namespace下面可以用不同的用户和用户组,甚至包括超级用户(默认情况下就会是超级用户)。docker默认不开启User Namespace的功能。
通过这个功能就能实现在宿主机中看起来是普通用户,在进程内是root的目的。
CGroup
CGroup术语:
- task(任务):系统的一个进程(Linux不区分进程和线程)
- cgroup(控制组):资源控制以cgroup为单位实现。
- sussystem(子系统):一个资源调度控制器,例如CPU、MEM
- hierarchy(层级):由一系列cgroup以一个树状结构排列而成,每个层级通过绑定对应的子系统进行资源控制。
个人对层级的理解是同一类子系统(一个或多个)的归类。这也好解释为什么一个人不能挂载到同一个层级的不同cgroup上。
此外,一个层级树上节点的资源是继承关系的。即一个task占用的资源不仅被他所在的cgroup管理,还被他的父辈cgroup管理。(通过在父cgroup上限制cpu的配额,发现子group上的任务运行明显变慢了进行证明)
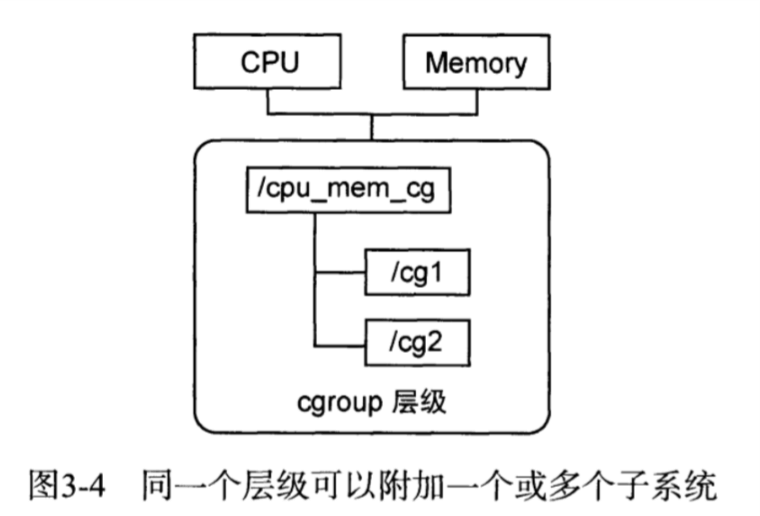
层级与子系统关系
同一个层级可以附加一个或多个子系统,例如下图的CPU、Memory都是子系统。
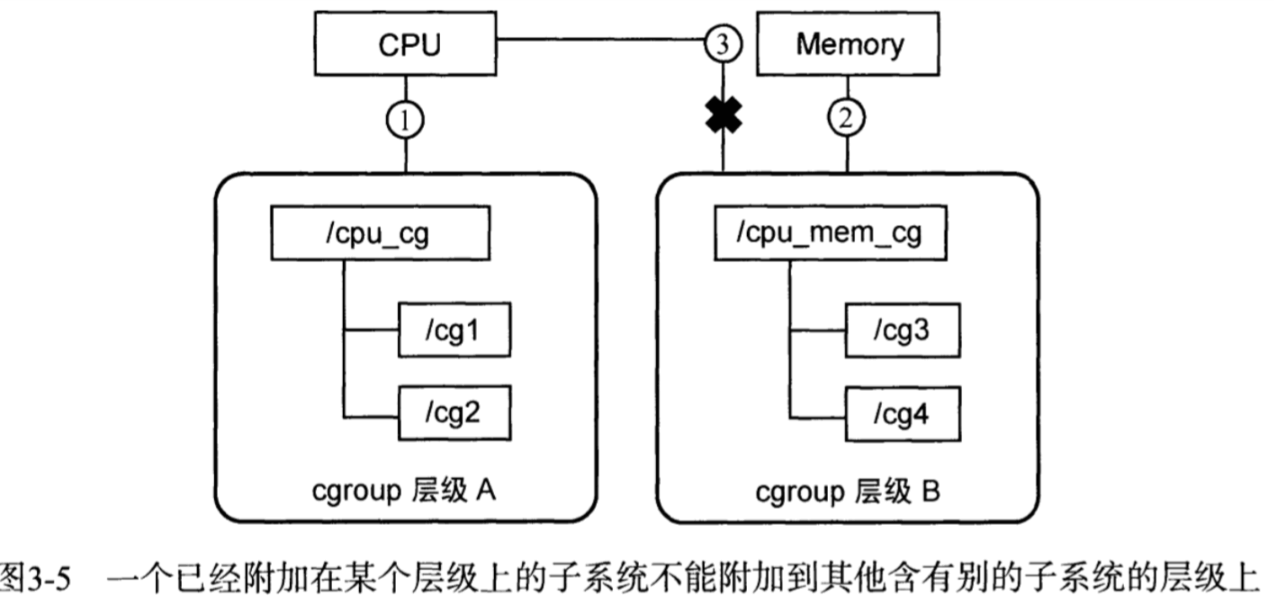
一个子系统可以附加到多个层级,当且仅当目标层级只有唯一一个子系统。如下图的层级B因为添加了Memory子系统,不能再添加CPU子系统。
有点不好理解。个人的理解是层级上如果有多个子系统,那么这些子系统不能再和其他层级share。
系统每次新建一个层级时,该系统上的所有任务默认加入这个新建层级的初始化cgroup,也称为root cgroup。对于
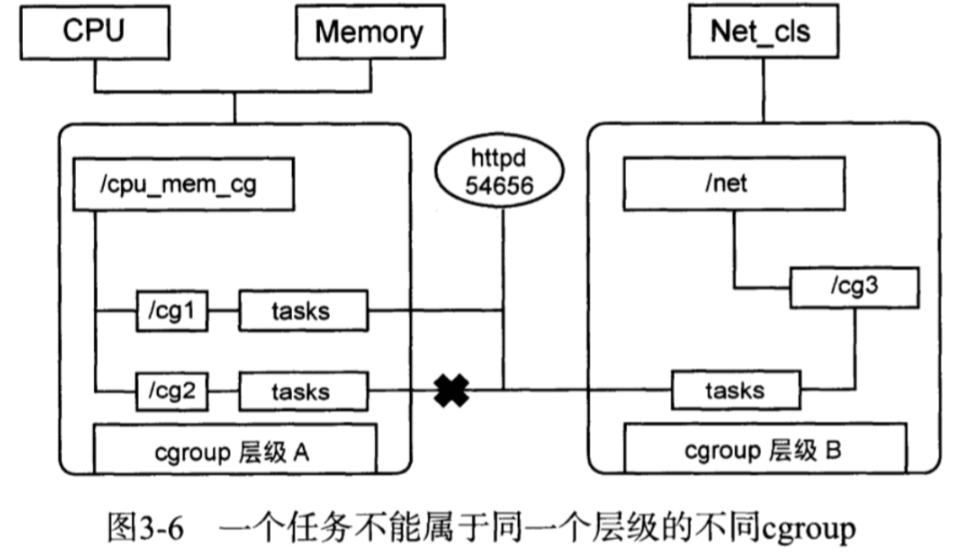
任务在fork或者clone的时候创建的子进程与原任务在同一个cgroup中,但是子任务允许被移动到不同的cgroup中。
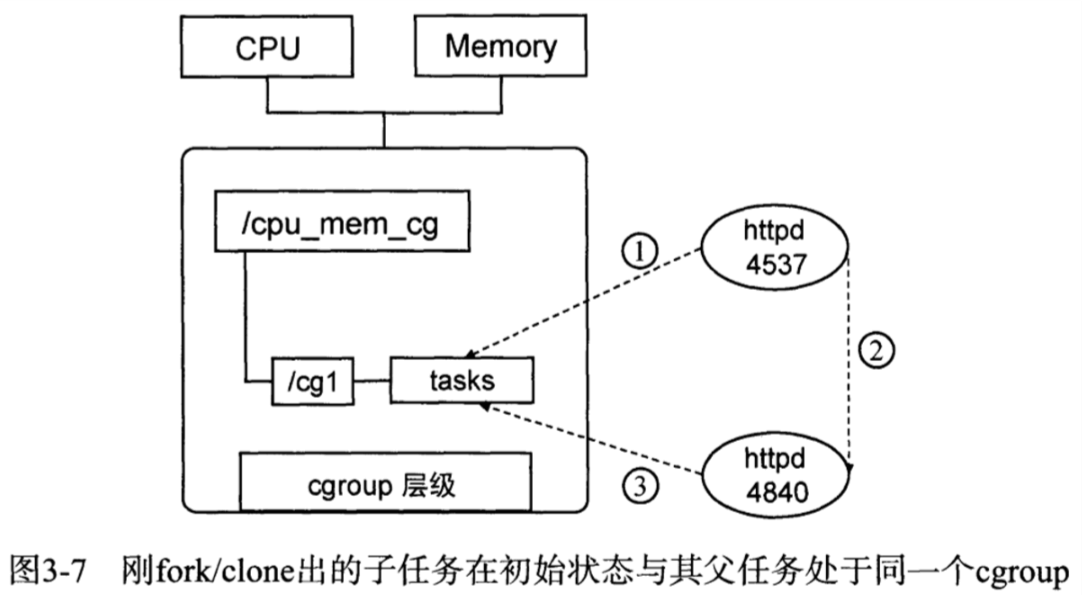
子系统
介绍
子系统实际上就是cgroups的资源控制器,每个子系统独立地控制一种资源。
1 | root@jingtao-HP-Z440-Workstation:/home/jingtao # lssubsys -a # 查看系统的子系统 |
cgroup的实现形式为一个文件系统,通过mount命令可以查看
1 | root@jingtao-HP-Z440-Workstation:/home/jingtao# mount -l | grep cgroup |
以CPU为例,在cpu子系统下docker层级的内容
1 | root@jingtao-HP-Z440-Workstation:~# tree /sys/fs/cgroup/cpu/docker/ |
实现原理
超出配额之后的处理措施
以Memory子系统为例,会在描述内存状态的mem_struct结构体中记录他所属的cgroup,当进程需要申请更多内存的时候,就会触发cgroup用量检测,超过cgroup的限制之后就会被拒绝;否则就允许申请,并进行记录。
进程所需要的内存超过它所属cgroup的限制之后,如果设置了OOM Control,那么进程会收到OOM信号,并结束。否则进程就会被挂起,进入睡眠状态,直到其他进程释放了足够多的资源。Docker中默认开启了OOM。
cgroup和任务之间的关系
cgroup与任务之间的关系是多对多,不直接关联,通过中间结构连接双向信息。每个任务结构体task_struct中都包含一个指针,可以查询到对应cgroup与各个子系统的状态;这些子系统状态中也包含了找到任务的指针。
Docker架构概览
Docker daemon负责将用户请求转化成系统调用,进而创建和管理容器。
松耦合结构,模块分工明确
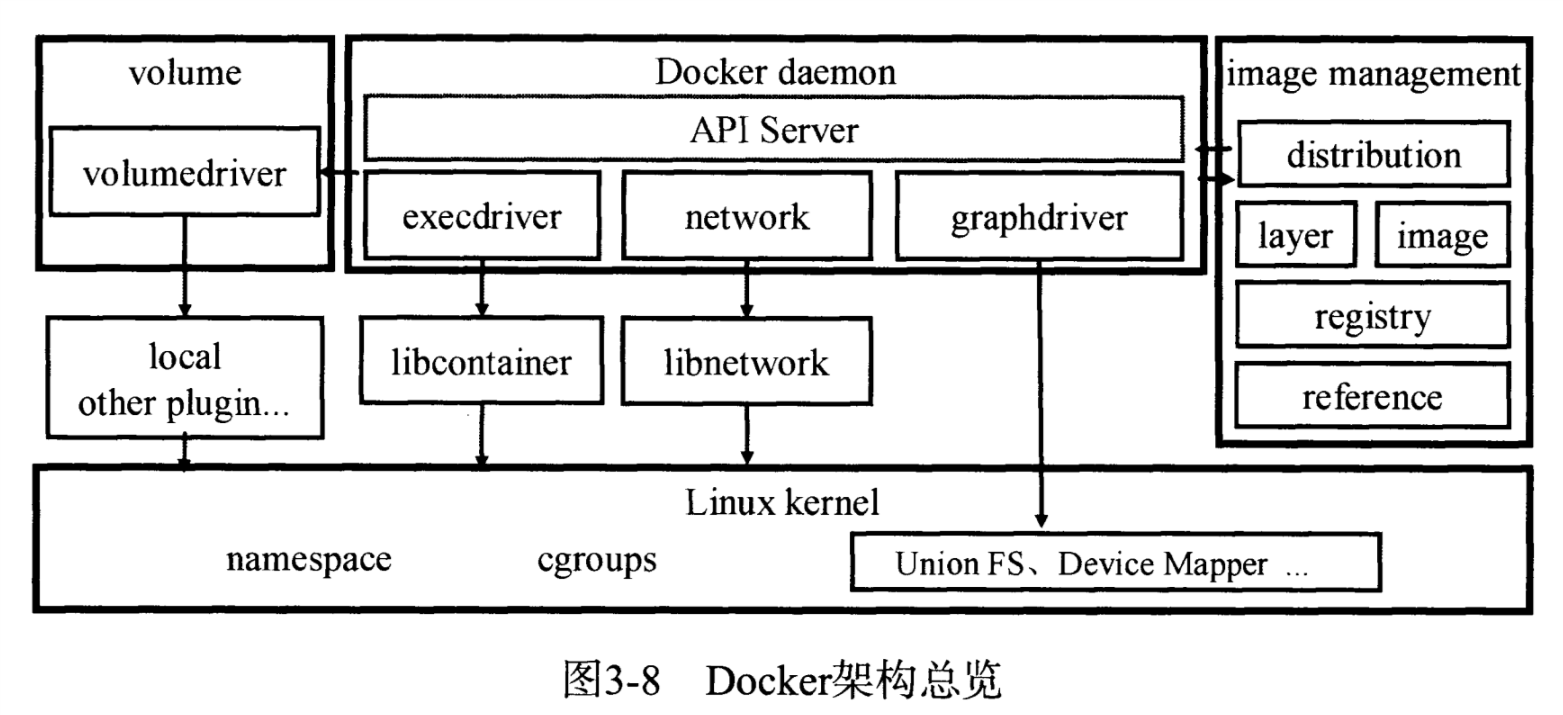
镜像管理
由如下几个部件组成
- distribution:(分配),负责与Docker registry交互,上传下载镜像以及存储于v2 registry有关的数据。
- registry:负责与Docker registry有关的身份验证、镜像查找、镜像验证等
- image:负责与镜像元数据有关的存储、查找,镜像层的索引、查找以及镜像tar包有关的导入、导出操作
- reference:负责存储本地所有镜像的repository和tag名,并维护与镜像ID之间的映射关系
- layer:负责与镜像层和容器层元数据有关的增删改查,并负责将镜像层的增删改查操作映射到实际存储镜像层文件系统的
graphdriver模块
Execdriver
是对Linux操作系统的namespaces、cgroups、apparmor、SELinux等容器运行所需的操作系统的进行的二次封装。这里重点关心libcontainer的具体实现,它是负责真正创建容器进程的组件。
Execdriver工作流程
Execdriver会根据Daemon提交过来的command信息(多来自Client),创建了一份可以供libcontainer解读的容器配置container(小写), 这是一个预先定义的模板,会根据用户指定的flag进行覆盖,如下Demo:
1 | container := &configs.Config{ |
创建好container容器配置之后,执行下面的步骤,完成容器的创建。
- 创建libcontainer构建容器需要的使用的进程对象
Process - 设置容器的输出管道,例如Docker daemon提供给libcontainer的pipes
- 使用名为
Factory的工厂类,根据传入的container创建逻辑上的容器Container(大写) - 执行
Container.Start(Process)启动物理容器 - execdriver执行Docker Daemon提供的
startCallback回调 - execdriver执行
Process.Wait等待Process完成所有的工作
Libcontainer工作方式
从上文的Execdriver完成容器调度的例子,可以发现libcontainer最主要的内容是Process、Container以及Factory这三个逻辑体的实现。和上文容器创建过程对应的伪代码如下。
1 | // 默认创建Linux的工厂类 |
用Factory创建逻辑容器Container
创建一个逻辑上的容器对象Container,包含了容器要运行的指令及其参数、namespace和cgroups配置参数等。由于需要和底层系统打交道,因此不同平台就需要创建出不同的“逻辑容器对象”(比如Linux容器和Windows容器)。Factory的Create操作主要完成如下的工作:
- 验证容器的根目录,容器ID和容器配置的内容是否合法
- 验证上述容器ID和现有容器不冲突
- 在根目录创建以ID为名的容器工作目录,默认为
/var/lib/docker/containers/{ID} - 返回Container对象,其中包含如下的信息:容器ID、容器工作目录、容器配置、初始化指令和参数(即dockerinit),以及Cgroup管理器
启动逻辑容器Container
Container包含了容器配置、控制等信息,是对不同操作系统下容器实现的抽象,是和上层应用程序沟通的接口,例如使用Container.Stats得到容器的资源使用情况,执行Container.Destory来销毁这个容器
参与容器创建的Process实例一共有两个
- Process:物理容器内进程的配置和IO的管理
- ParentProcess:在物理容器外部处理物理容器的启动工作,与
Container对象直接交互,在启动工作完成后,负责执行等待、发信号、获得容器内进程pid等管理工作(ParentProcess更像是一个接口,创建出一个initProcess的对象,仍然运行在调用者(Docker daemon)的进程上下文中,在下面的进程三个阶段的变种中有具体的总结)
Container.Start()启动过程有两个主要的工作
创建ParentProcess实例()
- 创建一个pipe,用来与容器内未来要运行的进程通信
- 根据Container的相关配置信息(启动命令的路径、命令参数、输入输出、执行命令的根目录以及pipe等)构建cmd对象(根据cmd对象可以创建容器中的第一个进程dockerinit )
- 为cmd设置环境变量
_LIBCONTAINER_INITTYPE=standard来告诉将来的容器进程当前执行的是init的操作,主要为了区分libcontainer进入已有容器执行子进程的情况,即docker exec的效果 - 将容器需要配置的namespace添加到cmd的Cloneflags中,表示将来的这个cmd要运行在上述的NS中。若需要user namespace,还要针对配置项进行用户映射,默认映射到宿主机的root用户上
- 将Container中的容器配置和Process中的Entrypoint信息合并为一份容器配置加入到ParentProcess中。
实际上ParentProcess是一个接口,真正创建的是一个initProcess的具体实现对象,他包含了cmd、pipe、cgroup和容器配置四部分。主要为了和setnsProcess进行区分。
执行
ParentProcess.start()来启动容器启动过程实际上就是
initProcess.start(),真正的docker容器就诞生了
用逻辑容器创建物理容器
initProcess.start()方法创建新物理容器的过程如下
- 使用exec包执行
initProcess.cmd,创建一个新的进程dockerinit,为他设置NS,clone出容器中第一个进程。对于libcontaier来说,这个命令来自于execdriver新建容器时加载daemon的initPath,即docker工作目录下的/var/lib/docker/init/dockerinit-{version}文件,dockerinit进程所在的namespace,即用户为最终的Docker容器指定的namespace(个人理解是一个专门来做容器内初始化的一个进程) - 把容器进程的pid加入cgroup中管理,至此容器的隔离环境已经初步创建完成
- 创建容器内部的网络设备,包括lo和veth
- 通过管道发送容器配置给dockerinit
- 通过管道等待dockerinit完成初始化,或者出错
ParentProcess(即initProcess)启动了一个子进程dockerinit作为容器内的初始进程完成
dockerinit通过调用reexec.init()完成初始化的工作,其具体的执行任务,由execdriver注册到reexec中的具体实现来决定的。对于libcontainer,这里注册的是Factory当中的StartInitialization()。具体流程如下:
- 创建pipe管道所需要的文件描述符
- 通过管道获取ParentProcess传来的容器配置,如namespace、网络等信息
- 从配置信息中获取并设置容器内的环境变量
_LIBCONTAINER_INITTYPE,区分创建还是在已存在的容器中执行命令 - 如果用户指定了-ipc -pid -uts参数,则dockerinit还需要把自己加入到用户指定的上述namespace中去
- 初始化网络设备,这些网络设备正式在initProcess中创建出来的,初始化包括:修改名称、分配MAC地址、设置MTU、添加IP地址和配置默认网关等
- 设置路由和RLIMIT参数
- 创建mount namespace,为挂载文件系统作准备
- 在上述mount namespace中设置挂载点,挂载rootfs和各类文件设备,比如/proc。然后通过pivot_root切换进程根路径到rootfs的根路径
- 写入hostname,加载profile等信息
- 比较父进程是否还是之前的父进程,若不是终止,若是继续
- 使用execv系统调用执行容器配置中的Args指定的命令(execv会保证继续执行的命令的进程还是dockerinit的PID信息
综上,容器进程发生了三个阶段的变化
- Docker daemon进程进行Factory创建Container、启动Container等准备工作,构建ParentProcess,并利用他创建了容器中的第一进程dockerinit
- dockerinit进程进行初始化工作
- 在初始化工作的最后,调用execv执行容器配置的命令
execv进程完全替换当前进程,不会创建新的进程
综上,Docker daemon进程和dockerinit进程之间通讯的方式是管道,通过关闭管道,让对方收到EOF信号的方式,让对方感知配置文件传输完毕和初始化工作的执行完毕
graphdriver
所有与容器镜像有关操作的最终执行者。graphdriver会在Docker的工作目录下维护一组与镜像层对应的目录,并记下镜像层之间的关系以及与具体的graphdriver实现相关的元数据。最终用户对镜像的操作都会转变成对这些目录文件以及元数据的增删改查,从而屏蔽不同文件存储系统(主要指联合文件系统)实现对于上层调用者的影响。
Docker镜像
Docker镜像是一个只读的Docker容器模板,包含启动Docker需要的文件系统结构和内容,是启动一个Docker容器的基础。在容器内部进程可见的文件系统是rootfs,即docker容器的根目录,由上下三层组成,但在容器内进程而言,他们是统一的一个文件系统,没有层级概念。
- 可读写部分:read-write layer 以及 volumes
- init-layer:dockerinit进程在初始化过程中修改的内容,例如hosts、resolv.conf、hostname等
- 只读层:read-only layer,镜像层
docker镜像的主要特点:
- 分层,通过分层达到了不同镜像之间共享镜像层的效果
- 写时复制(copy-on-write),每个容器在启动时将所有的镜像层以只读的形式挂载到一个挂载点上,然后再上面覆盖一个可读写的容器层,所有的变更操作都在容器层上进行
- 内容寻址,根据镜像层的内容计算一个hash值,作为镜像层的唯一ID,实现更高效的镜像层共享
- 联合挂载,用于将多个镜像层的文件系统挂载到一个挂载点实现统一的一个文件系统视图,是下层存储驱动(例如aufs)实现分层合并的方式。这并不是必须的,继续Device Mapper的快照技术也可以达到分层的效果,但并没有联合挂载这个概念
与Docker镜像有关的基本概念:
- registry:远程镜像仓库
- repository:是同一功能的镜像合集,通过版本进行区分
- manifest:存在于registry中作为Docker镜像的元数据文件,在pull、push、load、save中作为镜像结构和基础信息的描述文件
- image:在Docker内部的一个概念,用来存储一组镜像有关的元数据信息,主要包含镜像的架构(如amd64)、配置信息、包含所有镜像层的rootfs。
- layer:Docker用来管理镜像层的中间概念,主要存放了镜像层的diff_id(内容寻址算出来的ID)、size、cache-id(本地索引)和parent(所依赖的上层)等内容。diffID,基于镜像层的文件内容得到的,SHA256(镜像层文件内容);cacheID,随机生成的一个uuid,作为该层的文件的索引地址;
chainID,基于内容存储的索引,计算公式为chainID(n)=SHA256(chain(n-1) diffID(n)),如没有依赖的父镜像层,该层的diffID就是cacheID(不清楚用途)
voluemdriver
volume数据卷存储操作的最终执行者,负责volume的增删改查,屏蔽不同驱动器的实现的区别。默认实现的volumedriver是local,默认将文件存储于Docker根目录下的volume文件夹下面,其他的volumedriver是通过插件的方式实现的。
Network
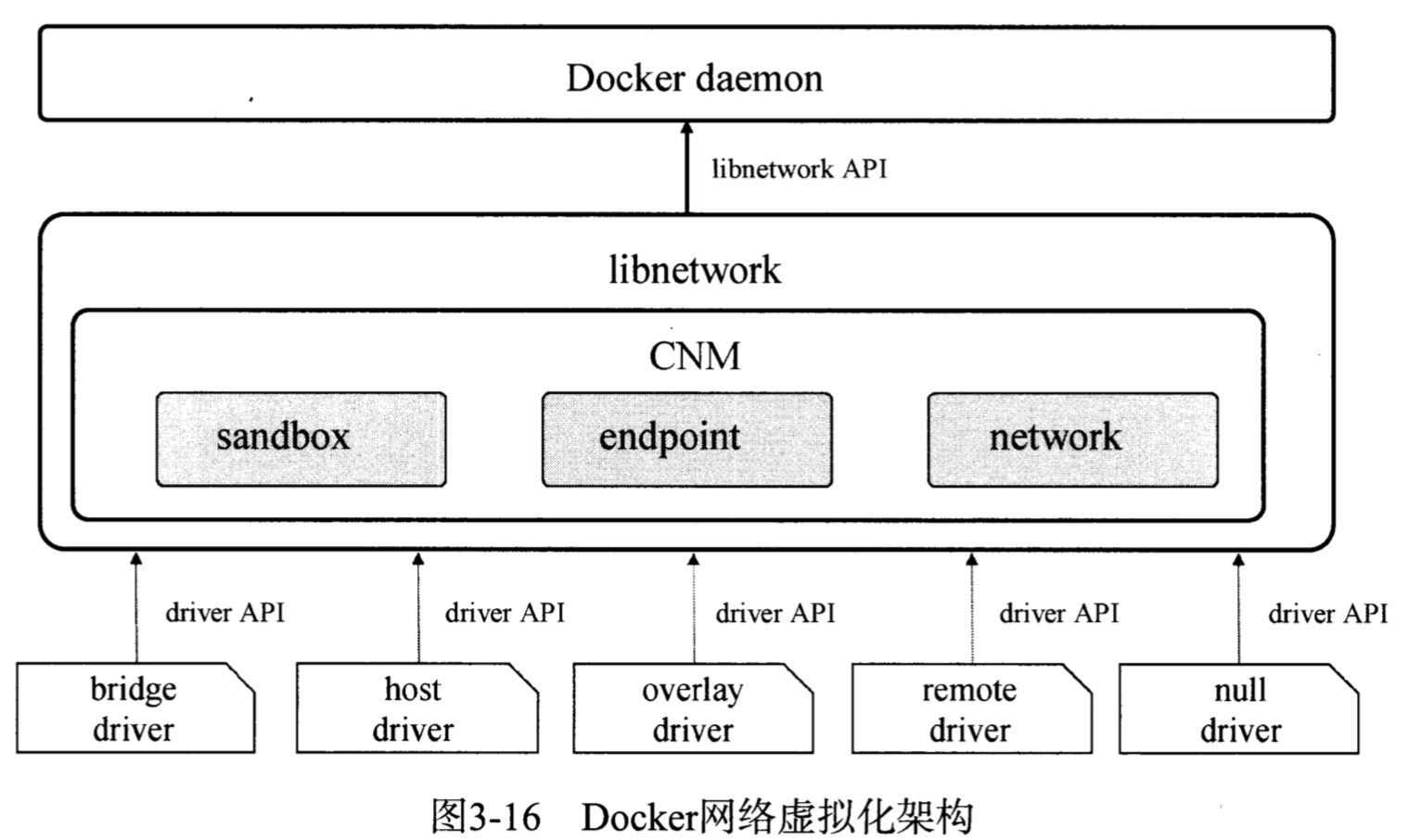
Docker网络架构,CNM(container network model),包含了三个核心组件sandbox,endpoint和network。
sandbox位于container中,network是可以连通的网络环境,endpoint只能属于一个sandbox和一个network,类似于连线。
此外libnetwork还提供5种内置驱动,这里重点关心默认使用的bridge驱动
- bridge驱动:Docker默认设置,使用该驱动时,libnetwork将创建出来的Docker容器连接到Docker网桥上,与外界通信使用NAT,增加了通信的复杂度,在复杂场景下使用会有诸多限制
- host驱动:使用该驱动时,libnetwork将不为Docker容器创建网络协议栈,即不创建独立的netwok namespace,Docker容器中的进程处于宿主机网络环境下,相当于Docker容器与宿主机共用同一个network namespace,使用宿主机的网卡、IP和端口等信息,但文件系统、进程表等还是与宿主机隔离。host模式很好解决了容器和外界通信的地址转换问题,可以直接使用宿主机的IP进行通信,不存在虚拟化网络带来的额外负担,但降低了网络层面的隔离性,引起网络资源的竞争和冲突,host驱动适用于容器集群规模不大的场景
- overlay驱动:该驱动采用IETF标准的VXLAN方式,并且是其中被普遍认为最适合大规模云计算虚拟化环境的SDN controller模式。使用过程需要一个额外的配置存储服务,如Consul、etcd、ZooKeeper,启动Docker Daemon时需要添加参数指定使用的配置存储服务地址
- remote驱动:该驱动实际上并未做真正的网络服务实现,而是调用了用户自行实现的网络驱动插件,实现了libnetwork的驱动可插件化
- null驱动:使用该驱动时,Docker容器拥有自己的network namespace,但是并不为Docker容器进行任何网络配置,Docker容器除了network namespace自带的loopback网卡外,没有其他任何网卡、IP、路由等信息,需要用户自行配置
核心三个组件之间的关系如下图所示。
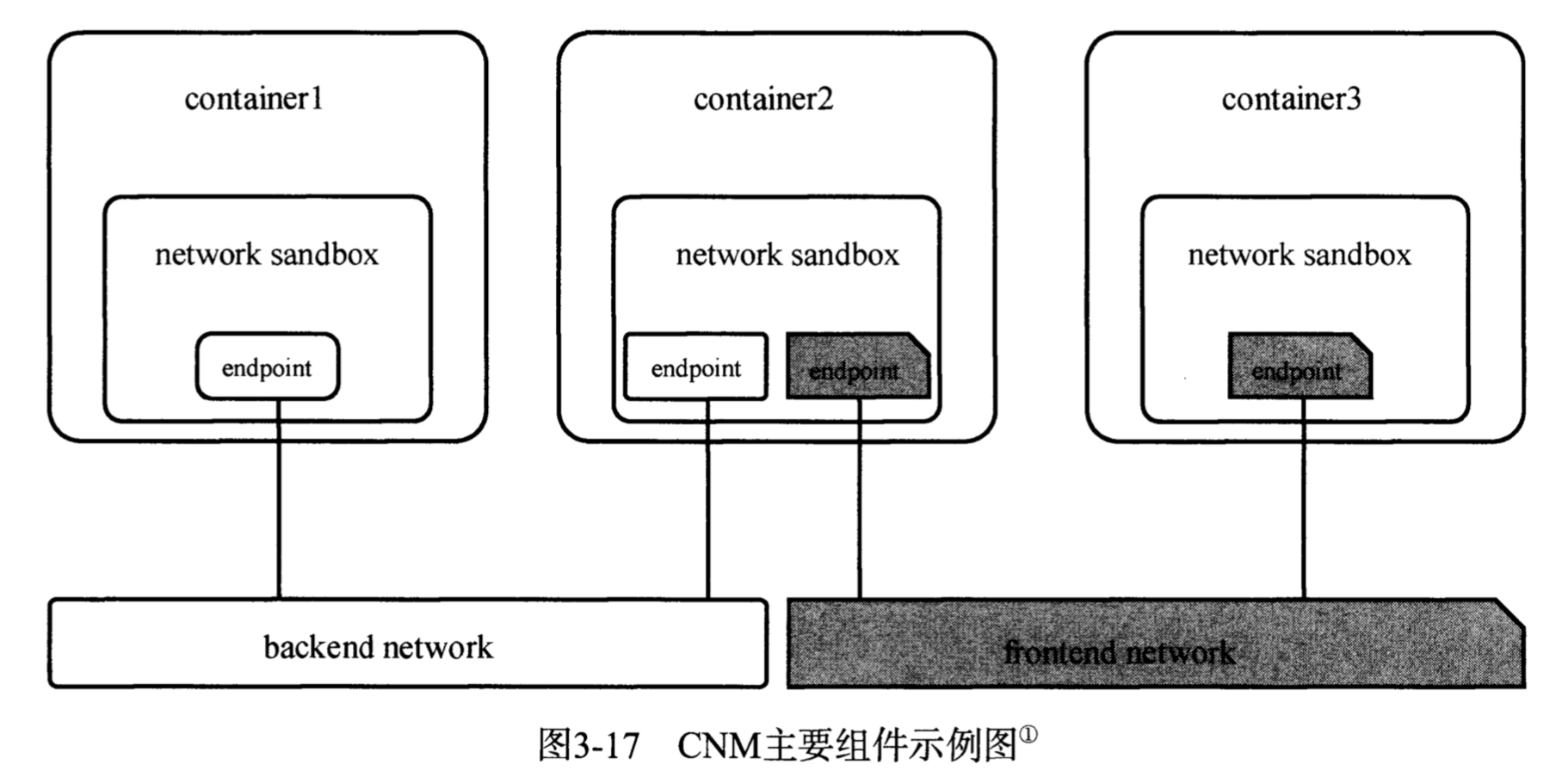
核心组件
Sandbox
一个沙盒包含了一个容器网络栈的信息。沙盒可以对容器的接口、路由和DNS设置等进行管理,沙盒的实现可以是Linux network namespace、FreeBSD Jail或者类似的机制,一个沙盒可以有多个端点和多个网络
Endpoint
一个端点可以加入一个沙盒和一个网络。端点的实现可以是veth pair、Open vSwitch内部端口或相似的设备,一个端点只可以属于一个网络并且只属于一个沙盒
Network
网络:一个网络是一组可以直接互相联通的端点。网络的实现可以是Linux Bridge、VLAN等,一个网络可以包含多个端点
驱动
Bridge
Docker创建一个网桥,容器通过连接到网桥上实现通讯,在和外界的通讯中,使用源地址转换(NAT机制)实现访问外网。在外网访问容器端口的时候通过目的地址转换来实现。网桥的本质是一个二层交换机,连接在网桥上的veth是交换机的端口。给网桥配置IP的目的是,让网桥充当与之连接容器的默认网关。(给网桥配置了IP地址,网桥实际上就是一个三层交换机了)
源地址转换(SNAT)例如下面的例子,下面这行命令的含义是,源地址为172.17.0.0/16的数据包(即Docker容器发出的数据),当不是从docker0网卡发出时做SNAT(源地址转换,将IP包的源地址替换为相应网卡的地址)
目的地址转换(DNAT)例如下面的例子,访问宿主机5000端口的流量转发到172.1.0.4的5000端口上(下面的第一条命令),此外Docker的forward规则默认允许所有的外部IP访问容器(下面的第二条命令)。可以通过在filter的DOCKER链上添加规则来对外部的IP访问作出限制(下面的第三条,只允许源地址是8.8.8.8的访问)
2
3
4
5
6
7
-A DOCKER ! -i docker0 -p tcp -m tcp --dport 5000 -j DNAT --to-destination 172.17.0.4:5000
...
*filter
-A DOCKER -d 172.17.0.4/32 ! -i docker0 -o docker0 -p tcp -m tcp --dport 5000 -j ACCEPT
...
-I DOCKER -i docker0 ! -s 8.8.8.8 -j DROP允许网桥进行交换的前提,是通过如下命令,允许流量在docker0网卡上进行交换(需要给Docker Daemon配置
--icc=true参数)
Link
在使用Bridge驱动的时候,很多时候为了安全会关闭交换机端口之间端口转发的功能(即--icc=false)。从而禁止容器之间的相互访问。若容器之间需要相互访问,则需要通过link命令把网络进行打通。
打通容器之间访问的方法是,例如下面的命令,允许172.17.0.2访问172.17.0.1的5432端口
2
-A DOCKER -s 172.17.0.1/32 -d 172.17.0.2/32 -i docker0 -o docker0 -p tcp -m tcp --sport 5432 -j ACCPET
旧版
旧版本的Link通过修改hosts来实现,因此旧版本的link只能单向,并且被link的容器需要已经创建好了,否则Link无发获取被link容器的地址。具体步骤如下:
以下面的场景为例
1 | docker run -d --name db postgres/10 |
在接收容器(发起访问的容器)中进行如下的配置
设置接收容器的环境变量
每增加一个源容器(被访问的容器),接收容器就设置一个名为
<alias>_NAME环境变量,alias为源容器的别名预先在源容器中设置的部分环境变量也会设置在接收容器的环境变量中,包括Dockerfile中使用ENV命令设置的,以及docker run命令中-e、--env=[]参数设置的,例如db中包含
doc=docker,则web中包含WEBDB_ENV_doc=docker接收容器同样会为源容器中暴露的端口设置环境变量,例如db容器IP为172.17.0.2,且暴露8080的tcp端口,web容器中会看到如下环境变量
1
2
3
4
5WEBDB_PORT_8080_TCP_ADDR=172.17.0.2
WEBDB_PORT_8080_TCP_PORT=8080
WEBDB_PORT_8080_TCP_PROTO=8080
WEBDB_PORT_8080_TCP=tcp://172.17.0.2:8080
WEBDB_PORT=tcp://172.17.0.2:8080更新接收容器的
/etc/hosts文件Docker容器的IP地址是不固定的,容器重启后IP地址可能与之前不同,在有link关系的两个容器中,接收容器包含有源容器的IP和环境变量,但源容器重启时,接收方容器中的环境变量并不会自动更新,因此link操作除将link信息保存在接收方容器中外,还在/etc/hosts中添加了一项源容器的IP和别名,用以来解析源容器的IP地址,并且当源容器重启后,会自动更新接收容器的/etc/hosts文件。
Docker容器/etc/hosts文件的设置是在容器启动时完成的,当一个容器重启后,自身的hosts文件和以自己为源容器的接收容器的hosts文件都会更新,保证link系统的正常工作。
新版
新版本的Link通过DNS来进行管理,因此Link可以是双向的,并且被link的容器不需要预先创建。
Daemon
API Server的配置和初始化
Daemon对象的创建和初始化过程
Daemon对象是一个具有完整功能的一个句柄。通过这个对象可以完成对所有驱动的调用。
Docker容器的配置信息
配置网络最大传输单元;监测网桥配置信息
检测系统支持及用户权限
是amd64架构的处理器以及内核版本3.10.0以上并有root权限
配置daemon的工作路径
/var/lib/docker的0700权限配置Docker容器所需的文件环境
总结如下,最新版的docker下的目录已经和这个介绍的不一样了,但文件夹的功能还是类似的

创建Docker Daemon网络
初始化execdriver
daemon对象诞生
恢复已有的Docker容器
参考和资料来源
- 图片来自与wbuntu
- network namespace内容来自理解Docker容器网络之Linux Network Namespace