简介
数据格式
数据源(Datasource),类似于数据库的表,每个数据源都由三部分组成:时间列 维度列 指标列。举例如下(其中的维度列由一系列key-value结构组成)

节点组成
Druid由三种类型的节点组成:
- 实时节点(Realtime Node):摄入实时数据,生成
Segment文件,同时兼顾查询任务 - 历史节点(Historical Node):加载已经生成好的数据文件,以供查询使用
- 查询节点(Broker Node):对外提供数据查询服务,同时从历史节点和实时节点查询数据,合并返回给调用方
- 协调节点(Coordinator Node):负责历史节点的数据负载均衡,通过规则管理数据的生命周期
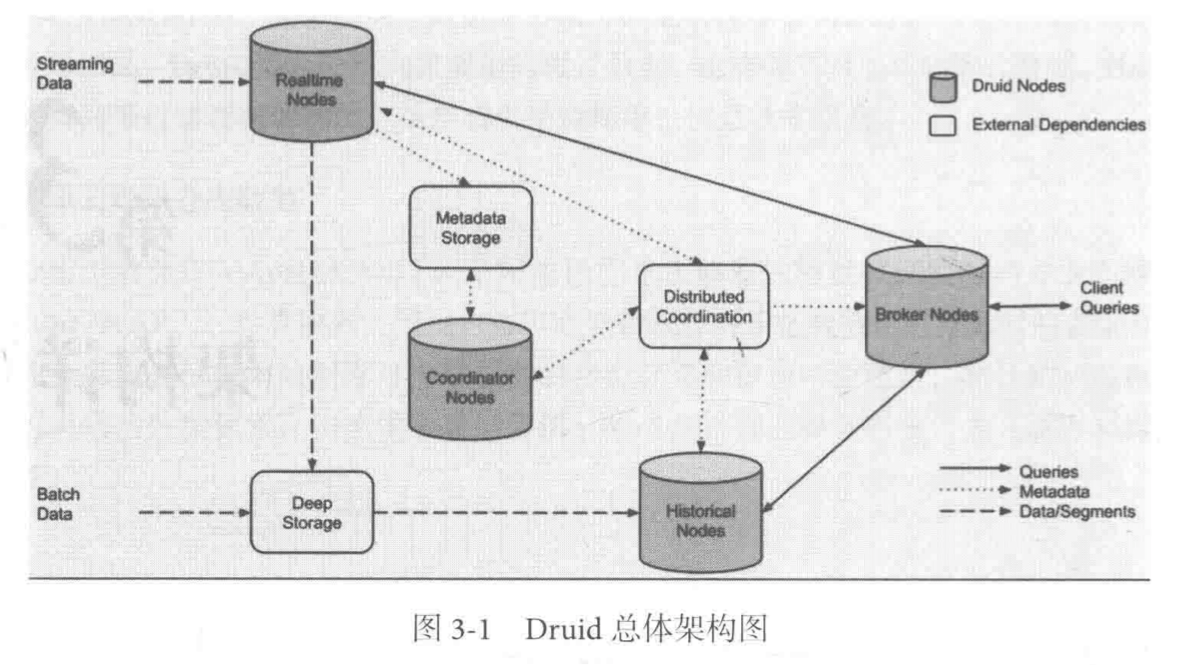
外部依赖
Druid需要三种外部依赖:
- 元数据库(Metastore):存储Druid集群的原始数据信息,比如Segment的相关信息,一般使用Mysql或PostgreSQL
- 分布式协调服务(Coordination):提供一致性协调组件,通常为Zookeeper
- 数据文件存储库(DeepStorage):存放生成的Segment数据文件,并供历史节点下载。对单点集群可以是本地磁盘,对与分布式集群一般是HDFS或NFS
设计原则
Druid三个设计原则:
快速查询:部分数据聚+内存化+索引
- 部分数据聚合:例如提供1分钟、5分钟、1小时、1天等的聚合粒度
- 内存化:使用Bitmap和各种压缩技术,实现内存的最大化利用
- 索引:维护了一些倒排索引,加快AND和OR等计算操作
水平扩展能力:分布式数据+并行化查询
- 每个Segment有最大大小,支持segment的分区操作
- 支持Count、Mean、Variance等并行化的查询
- 对于不支持并行化查询的median,Druid暂不支持
实时分析:不可变得过去,只追加的未来
- 事件一旦进入系统就不可以被改变
技术特点
- 数据吞吐量大,几十亿到几百亿的事件/day
- 支持流式数据摄入和实时
- 查询灵活且快
- 社区支持力度大
Druid关键技术
日志结构合并树
日志结构合并树(log-structured Merge-Tree,简称LSMT)适合数据的频繁插入。具体实现上有两棵树:
C0树存放在
memtable(内存缓存)中,负责接收新的数据,插入更新,以及读请求C1树存放在
sstable(硬盘)上,由C0树冲写到磁盘上形成的,主要负责读操作,特点是有序且不被更改。除此之外,LSM-tree还使用日志文件(commit log)来为数据恢复做保障。所有的新插入和更新操作都首先被记录到
commit-log中,该操作成为write ahead log。然后写到memtable,达到一定数量时,数据会从memtable冲写到sstable,并抛弃相关的commit-log数据;memtable和sstable中可同时提供查询,当memtable中出现问题,会从sstable和commit-log中恢复数据。Hbase中的LSM-tree和Druid中的类比
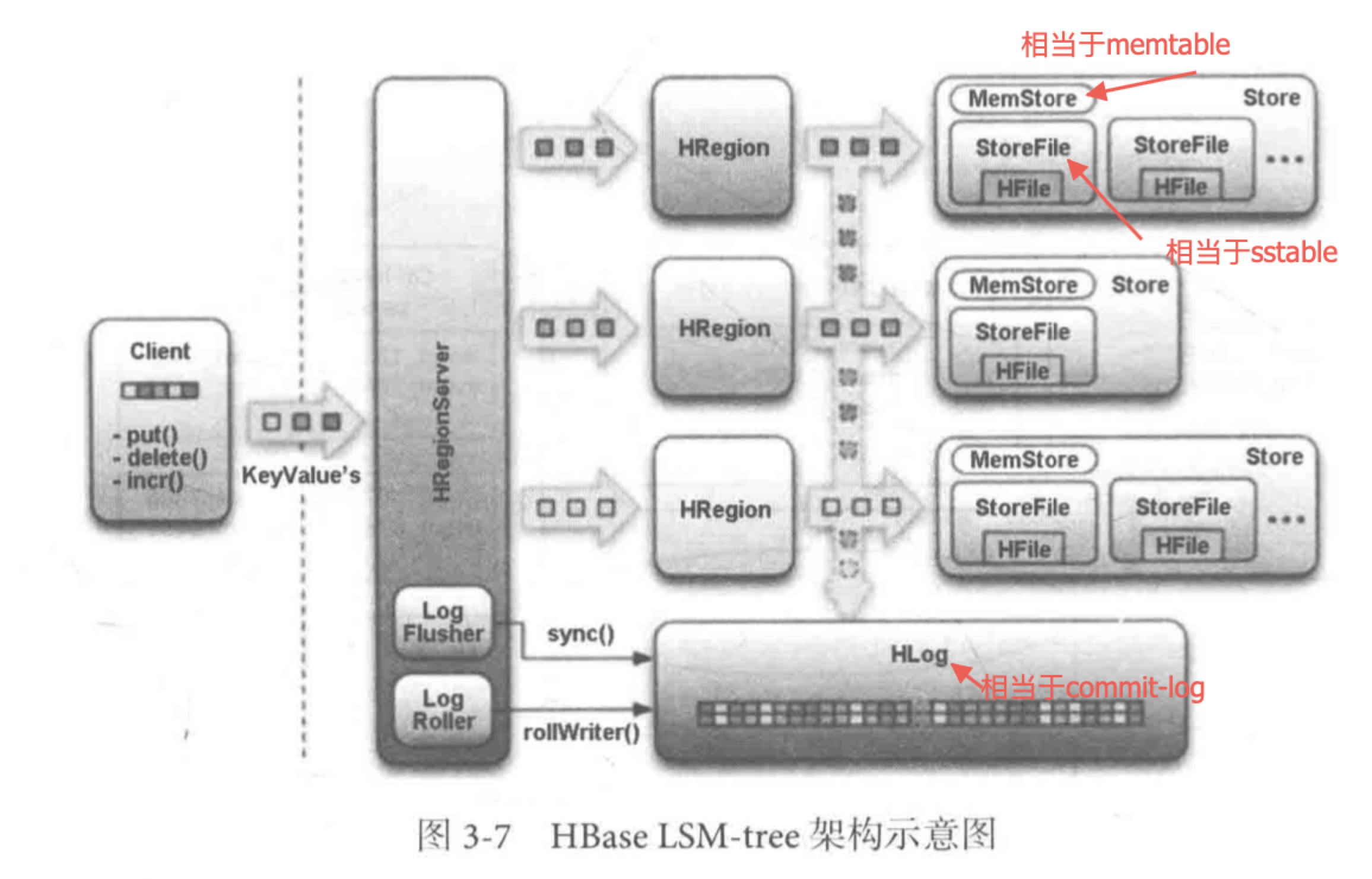
Druid不提供commit-log的功能,实时数据首先会直接加载到实时节点的内存中的堆结构缓冲区(相当于memtable),当条件满足时,缓冲区的数据会被冲写到硬盘上形成一个数据块(Segment Split)同时实时节点又会将新生成的数据块加载到内存的非堆区,所以堆结构和非堆结构中的数据都会被Broker Node查询到。
- 实时节点会周期性将磁盘上同一时间段内生成的所有数据块合并为一个大的数据块(Segment),这个过程叫做 Segment Merge操作(相当于LSM-tree架构中的数据合并操作)。具体有Firehose模型(不理解),消费实时数据,有Plumber模型按照指定的周期,将本周器的数据库合并成一个大的segment数据文件(不理解)。
- 合并好的Segment会被立即上传到文件存储库中,同时将Segment的元数据存储到MetaStore(即Mysql)中,随后协调节点会指导历史节点到文件存储库中将新的segment下载到本地磁盘
- 下载完成后,历史节点会通过协调节点在集群中声明,此刻开始负责提供该Segment的查询服务
- 实时节点收到声明之后,停止该segment的查询服务
- 实时节点数据分布结构如下图所示
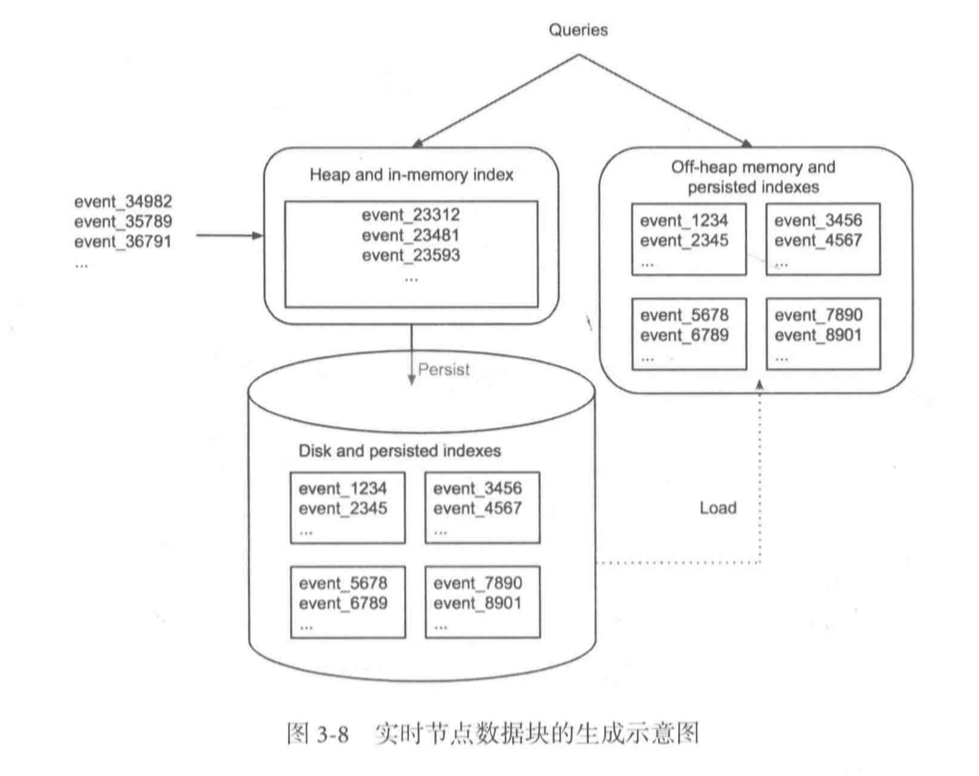
- 由于没有commit-log功能,当节点失效时,Druid会采用两种方式来实现数据完整性
- 让失效的节点恢复过来
- 重新接收数据(例如kafka的精确消费模式)
BitMap倒排索引
作用:根据指定维度列的查询,快速获得行所在的位置
例如:针对下图的查询语句
1 | select clicks from datasource where gender='Male' and country='USA' |

若没有索引结构,只能顺序遍历,找到满足要求的行。使用bitmap之后,可以为每一列添加索引
- gender
- Male
1 1 1 1
- Male
- country
- USA
1 1 0 0 - UK
0 0 1 1
- USA
面对上述查询,只需要USA的bitmap和Male的bitmap做AND操作,就可以找出满足要求的行
bitmap的构建时机是,数据从内存持久化到硬盘的时候进行的
bitmap的构建原理:每一个维度列的内容都是可以被枚举的,例如上述country,会构建字典结构
- ValueToId:
- <USA, 0>, <UK, 1>
- IdToValue:
- <0, USA>, <1, UK>
以此类推之后,指标列的具体存储内容就可以由id来代替,实现可观的数据压缩功能。
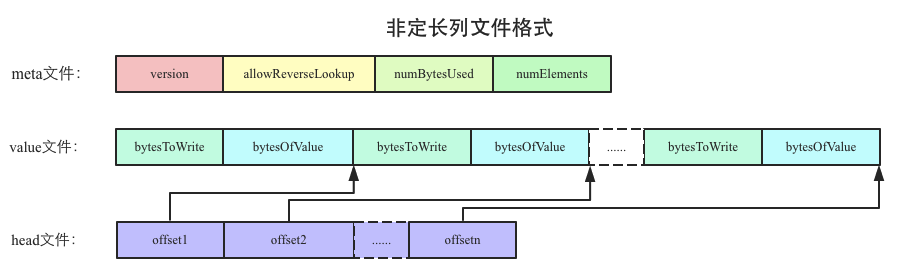
bitmap索引的数据压缩:bitmap索引中会存在大量的连续1或者0,很适合进行数据压缩
每个维度列的字典信息和数据列的信息都会采用如下的存储方式进行存储。
数据存储结构
DataSource是逻辑概念,Segment是数据的实际物理存储格式。Druid通常执行Count,Sum,Mean等操作,因此可以执行数据聚合。Druid 基于Datasource的结构进行数据存储时,即可选择对任意的指标列进行聚合操作(Roll Up)操作。主要基于维度列和时间范围两种情况。
- 同维度列的值做聚合:所有维度列的值都相同的时候,这一类行数据满足聚合操作。
- 对指定时间粒度的值做聚合:比如时间在同一分钟内的数据做聚合
聚合操作相当于对表的所有列做了Group By操作。下图实际执行的语句是:Group By timestamp, publisher, advertiser, gender, country ::impressions = COUNT(1), clicks=SUM(click), revenue=SUM(price)。对下图数据进行聚合后的效果
Segment的横纵向切割:
- 横向切割:Druid将不同时间 范围的数据存储在不同的Segment中,便于时间范围内的数据查询
- 纵向切割,面向列进行数据压缩处理,使用bitmap等技术对数据的访问进行优化