Etcd
容器云中以微服务方式构建的应用中,服务发现、服务状态发布和订阅等模块发挥了连接各个微服务的重要作用。而其中的关键性技术就是高可用的配置中心,K8s 使用的配置中心是etcd,它是一个键值存储仓库,用于配置共享和服务发现,有如下的几个特点:
- 简单:使用http+json的API,用curl命令就可使用
- 安全:可选SSL客户认证机制
- 快速:每个实例每秒支持一千次写操作
- 可信:使用raft算法,充分实现分布式
etcd推荐存储的是数据类型是数据量较小,但是更新访问频繁的情况。
Etcd使用场景
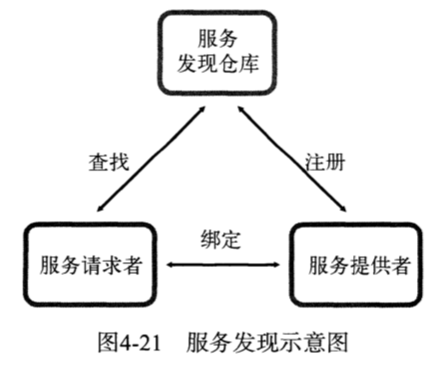
服务发现
一个服务发现系统需要如下几个特性进行支撑:
- 一个强一致性、高可用的服务存储目录
- 一种注册服务和监控服务监控状态的机制
- 一种查找和连接服务的机制
etcd支持用户注册一个键值对,并设置key的TTL,定时保持服务心跳以达到监控健康状态的效果。通过etcd主题下注册的服务,也能在对应主题下被查找到。
TODO 好奇ETCD和下文中的例如podStore实现数据同步的
资源类型
Pod
Pod是K8s创建、调度和管理的基本单元。pod内共享network、IPC、UTS namespace,并通过volume共享一部分存储。即pod中的容器:
- 共享网络资源,同时pod是IP等网络资源分配的基本单位。
- 通过将volume挂载到同属一个pod的多个Docker容器,共享存储。
- Pod中应用程序可以通过System V IPC或POSIX消息队列进行通信。
- 共享主机名
Service
简介
service是一簇pod的代理。它主要由一个IP地址和一个label selector组成。IP地址在Service被创建时就独一无二的被指定。可以根据配置将流量从service上指定的端口发送到label selector命中pod的端口上
实现原理
kubernetes在每个节点上都运行一个kube-proxy,它是负责实现service的主要组件。kube-proxy有两种工作模式userspace和iptables
userspace
对每个service,kube-proxy都会在宿主机上随机监听一个端口与这个service对应起来,并在宿主机上建立起iptables规则,将Service IP:Service Port的流量重定向到上述端口。再经过kube-proxy的代理到某个后端pod,kube-proxy会维护本地端口与service的映射关系。以及service代理的pod清单,至于选择哪个pod,则由路由策略决定(例如 Round-Robin)。
iptables
在该模式下kube-proxy将只创建及维护iptables的路由规则,其余的工作均由内和态的iptables完成。
自发现机制
自发现机制在service中主要指一旦一个service被创建,需要让所有的pod感知到这个service的ip和端口信息。实现这一目标也有两种方法
环境变量
kubelet创建pod的时候会自动添加所有的可用的service环境变量到该pod中,如有需要,这些环境变量就被注入到pod容器里。这些环境变量诸如{SVCNAME}_SERVICE_HOST,{SVCNAME}_SERVICE_PORT。
这种方法和旧版本的link的实现思路很像。但在service中,该步骤只发生在pod的创建时,并不会被负责更新。
DNS
通过添加一个可选的组件DNS服务器来实现,每个service会自动获得一个my-service.my-ns的域名。
外部可路由
上述的自发现机制都是在Kubernetes集群内部讨论的,也就是在Kubernetes的内网中实现的。实际上Service可以分为3种类型,ClusterIP、NodePort和LoadBalancer。其中ClusterIP是基本的类型,即只能在集群内部进行访问
NodePort
系统会从service-node-port-range中为其分配一个端口,并且在每个工作节点上都打开该端口。此时在集群外部通过<NodeIP>:spec.ports[*].nodePort就可以访问到这个service。
LoadBalancer
需要云服务器提供商的支持,其会将外部loadbalancer的流量导到后端pod中。
External IP
通过外部IP池给service额外分配一个公网IP,实现集群外的访问。
核心组件
框架组成
Kubernetes整体框架图,如下图所示。
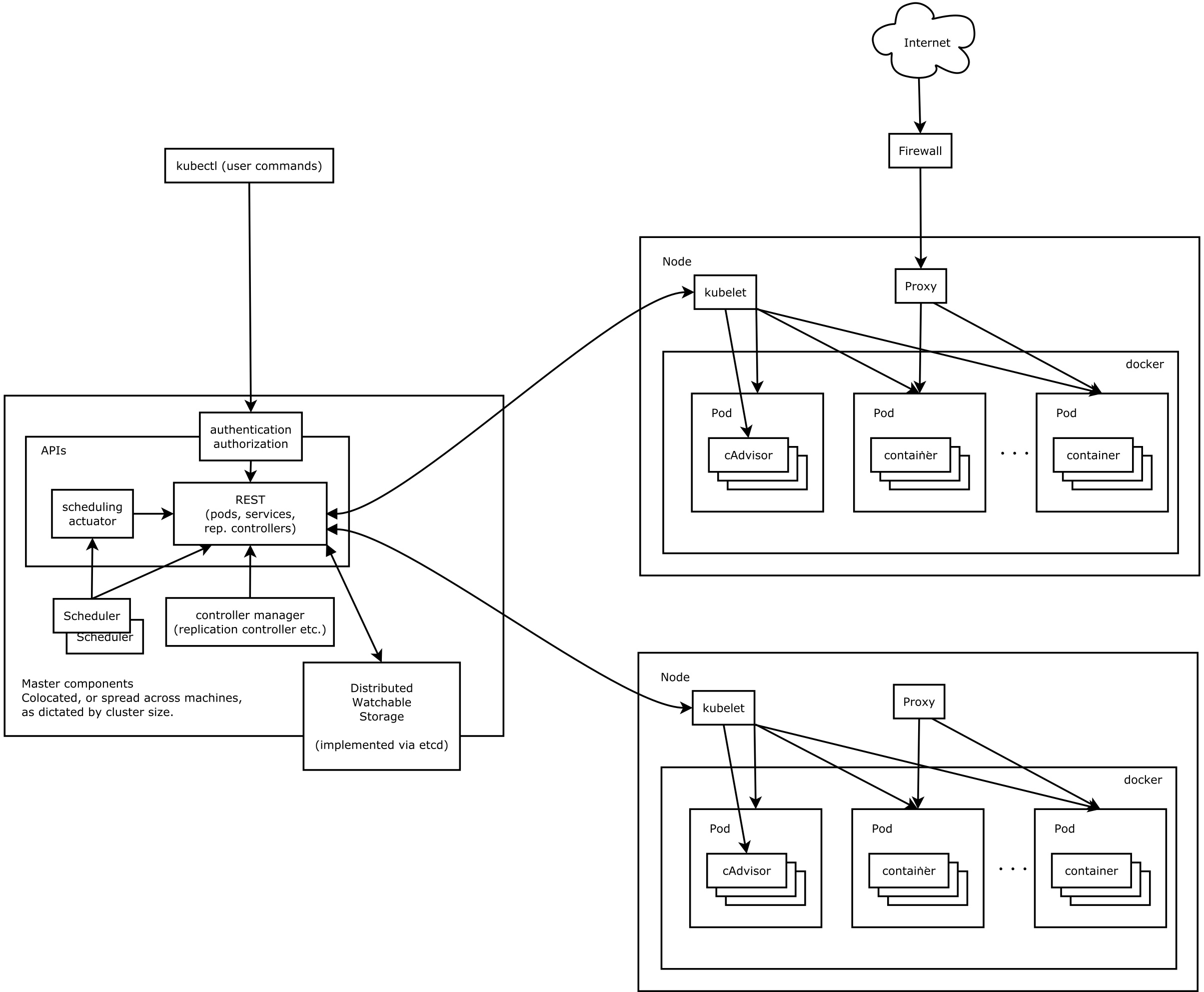
主要有master和slave两大部分组成。master控制节点上运行了3个重要的组件
- APIServer负责响应用户的管理请求,进行指挥协调等工作
- Scheduler将待调度的Pod绑定到合适的工作节点上
- Controller Manager是一组控制器合集,负责控制管理对应的资源,如replication、service和node等
slave控制节点上运行了两个重要的组件
- kubelet 负责管理和维护节点上的所有容器
- kube-proxy 负责将service的流量转发到对应的endpoint上
Master
Scheduler
Scheduler会判断pod适合部署在哪些机器上。调度策略分为两阶段:Predicates和Priorities,第一阶段负责回答能不能,第二阶段回答优先级有多高。
Predicates
判断是否可以的标准有:
- PodFitsHostPort:容器的端口和宿主机的端口是否冲突
- PodFitsResources:node上的资源是否够用,包括最大Pod数量、CPU以及MEM等
- NoDiskConflict:容器挂载卷是否冲突
- NoColumeZoneConflict:也是挂载卷的检查
- MatchNodeSelector:用户声明的主机标签和主机是否兼容
- HostName:是否是用户指定的主机
Priorities
判断优先级的标准有:
- LeastRequestedPriority:主机的节点负载越低得分越高。
- BalancedResourceAllocation:更偏好CPU和MEM负载均衡的节点
- SelectorSpreadPriority:高可用性,评估分散程度
- 。。。
Controller Manager
Controller Manager 是运行在集群master节点上,是基于pod API上的一个独立服务,他管理着Kubernetes集群中的各种控制器,这些控制器会默默管控这些资源,使他们满足用户的预期。控制器主要有
- 服务器端点(endpoint)控制器
- 副本管理(replication)控制器
- 垃圾回收(gc)控制器
- 节点(node)控制器
- 服务控制器
- 路由控制器
- 资源配额控制器
- namespace控制器
- horizontal控制器
- daemon set控制器
- job控制器
- deployment控制器
- replicaSet控制器
- persistent volume 控制器
endpoint controller
一个endpoint包含了一个service所有对应的后端IP和端口。endpoint controller 是endpoint对象的维护者,需要在service或者pod的期待状态或者实际状态发生变化时向APIServer发送请求,调整系统中的endpoint的对象。所以包含了两个缓存池:
- serviceStore
- podStore
他们通过controller的reflector机制实现和etcd的数据同步。
replication controller
负责保证rc管理的pod期望副本数量与实际运行的pod数量匹配。其包含了两个缓存池
- rcStore
- podStore
gc controller
Slave
Kubelet
负责管理和维护在这台主机上运行的所有容器。本质上是使得pod的运行状态和他的期望值spec一致。
启动过程
根据配置文件启动主进程KubeletServer
进行初始化工作
- 创建一个APIServer的客户端
- 上一步骤成功之后,会再创建一个APIServer的客户端用于向APIServer发送event对象
- 初始化cloud provider,非必需
- 创建并启动cAdvisor服务进程,返回一个cAdvisor的http客户端
- 创建ContainerManager,为Docker daemon、kubelet等进程创建cGroups,确保他们使用的资源在限额内
- 设置kubelet进程应用OOMScoreAdj值,使得kubelet在内存不足时是最不容易被杀死的进程
- 配置kubelet支持的pod配置方式,包括文件、url以及APIServer
在初始化工作完成之后,启动一个真正的kubelet进程
创建工作节点本地的service和node的cache,并且使用list/watch机制持续对其更新
创建DiskSpaceManager,用以与cAdvisor配合进行工作节点的磁盘管理
创建ContainerRefManager,用以记录每个container及其对应的引用的映射关系
创建OOMWatcher,用以从cAdvisor中获取系统的内存溢出事件
创建kubelet网络插件
创建LivenessManager,用以维护容器及其对应的probe结果的映射关系,用以进行pod的健康检查
创建podCache,用以缓存pod本地状态
创建podManager,用以存储和管理对pod的访问。
kubelet支持3种更新pod的方式,其中的通过文件和url创建的pod是不能自动被APIServer感知的,称其为static pod,为了监控这些pod的状态,kubelet会为每个static pod在相同的namespace下创建一个同名的mirror pod,用以反应static pod的运行状态
配置hairpin NAT
创建container runtime,支持docker和rkt。
创建PLEG,严密监视容器的运行状态,避免了轮询容器状态造成的代价开销
创建镜像垃圾回收对象containerGC
创建imageManager,管理容器镜像的生命周期,处理镜像的垃圾回收工作
创建statusManager,用以向APIServer同步pod实际状态的更新
创建probeManager,用做pod健康检查的探针
初始化volume插件
创建RuntimeCache,用以缓存pod列表
创建reasonCache,用以缓存每个容器对应的最新的失败原因信息
创建podWorker。每个pod将对应一个podWorker用以同步pod状态信息
根据Runonce的值选择运行的模式,执行一次便退出,还是持续的后台运行
启用kebelet Server的功能,他将根据admin的配置创建HTTP Server或HTTPS Server
与cAdvisor交互
通过cAdvisor抓取Docker容器和宿主机资源信息。具体信息如下
- Docker容器信息
- 绝对容器名称
- 子容器列表
- 每个容器所能使用的资源限制值和最近一段时间(由cAdvisor全局设置)容器详细的资源使用情况
- 宿主机信息
- CPU核心数
- 内存总容量
- 磁盘容量信息
垃圾回收机制
Docker 容器的垃圾回收机制
容器回收策略考虑到的因素有
- MinAge:某个容器垃圾回收前距离创建时间的最小值
- MaxPerPodContainer:每个pod最多留有的停止的相同容器名的容器数目
- MaxContainers:每个工作节点最多拥有的容器数目
垃圾回收过程如下:
- 获取可以被kubelet垃圾回收的容器
- 先获取由kubelet创建(通过命名规范进行约束)的容器信息,遍历出所有可回收的容器:已经停止,并且创建时间距离现在已经达到了预定的MinAge
- 将这些容器根据创建时间进行排序,创建时间越早,越靠前。排序的内容除了容器名之外,还有所属pod的名称。没有找到对应pod的容器,pod名会被标记为unidentifiedContainers。
- 根据垃圾回收策略回收镜像
- 先删除unidentifiedContainers以及被删除的pod对应的容器,这部分的容器删除不需要考虑其他的策略
- MaxPerPodContainer,根据该参数,删除多出的容器及其日志存储目录,先创建的容器会被先删除
- 根据MaxContainers的值,如果容器的数目超过限制,
Docker 镜像的垃圾回收机制
参考和资料来源
- deployment实现原理来自详解 Kubernetes Deployment 的实现原理