太过混乱,重新整理在操作系统知识点汇总
专题整理
进程下的多线程
在Linux下,线程是CPU调度的基本单位,线程会有自己独立的PID,可以使用pstree -pu来查看。
线程的种类
线程可以分为内核级线程和用户级线程
- 内核级线程是内核知道的线程,操作系统对内核级线程的调度,是可以在多核上并行的
- 用户级线程的存在是操作系统不知道的,由进程的线程库创建和管理,每次操作系统调度到该进程的时候,由进程库决定当前运行哪一个线程(可以理解是一个二级调度)
线程的栈的位置
进程中的多线程,除了主线程之外,其他线程的栈空间都在进程的堆空间上创建的。为了避免线程之间的栈空间踩踏,线程栈之间还会有以小块guardsize用来隔离保护各自的栈空间,一旦另一个线程踏入到这个隔离区,就会引发段错误。
参考github上的一份大佬的面试笔记,对书中的内容进行归纳整理。
之所以将两本书放在一篇博客,因为《操作系统导论》不想看了,懒鬼如我。。。
《UNIX 环境高级编程》
《Advanced Programming in the UNIX environment》
第三章 文件IO
3.10 文件共享
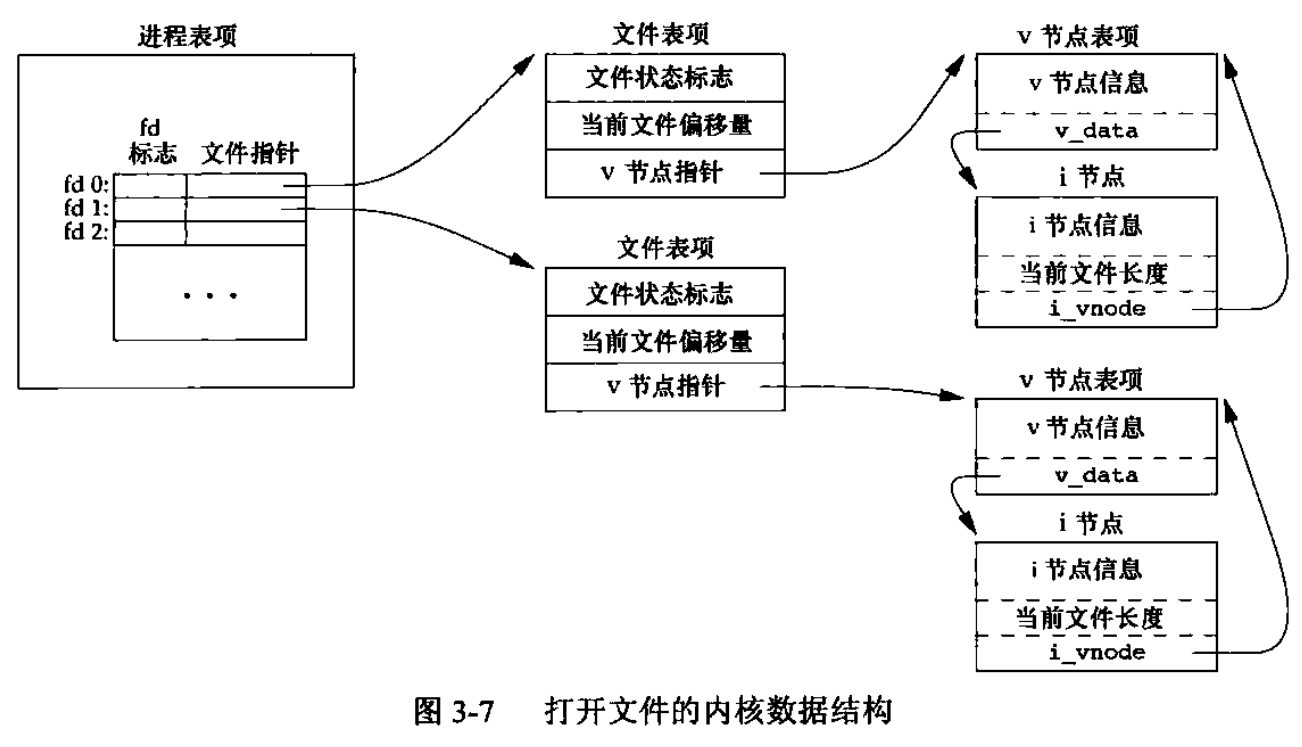
打开文件在内核的数据结构:
- 文件表项
- 文件的状态标志(读、写、添加、非阻塞等等)
- 当前文件偏移量
- 指向该文件v节点的指针
- v/i 节点表项
- 每一个打开的文件或者设备都有一个v节点
v-node结构。包含了文件类型和对此文件各种函数操作的指针 - 对于大多数文件,还会有一个i节点(
i-node索引节点),是在打开文件时从磁盘上读入内存的,所以文件的相关信息都是随时可用的。包括:- 文件的所有者
- 文件的长度
- 指向文件实际数据块在磁盘上所在位置的指针
- 每一个打开的文件或者设备都有一个v节点
3.11 原子操作
向一个文件追加或者创建一个文件的时候,都会有原子操作的需求
文件追加,会合并定位操作和文件写操作
文件创建,会合并判断文件是否存在和文件创建操作
第四章 文件和目录
4.5 设置用户ID和设置组ID
与进程相关联的ID有如下三大类:
- 用于判断进程实际所有者
- 实际用户 ID
- 实际组 ID
- 用于文件访问权限检查
- 有效用户 ID
- 有效组 ID
- 附属组 ID
- 由exec函数保存
- 保存的设置用户 ID
- 保存的设置组 ID
可以在文件模式字中设置一个特殊标志,使得“当执行此文件时,设置进程的有效ID为文件所有者的ID”,具体是用户ID还是组ID,可以通过不同的特殊标志来控制。通过该种方式可以让进程权限转换到其执行文件的所属用户的权限,来执行某些特殊的工作,Eg:任何用户都可以执行passwd命令,来修改只有超级用户才有写权限的/etc/passwd和/etc/shadow文件。此类程序编写的安全性需要格外注意。
4.6 文件访问权限
所有文件类型(目录,字符特别文件等)都有访问权限,每个文件有9种访问权限位:
用户读、用户写、用户执行; 组读、组写、组执行; 其他读、其他写、其他执行
通常用u表示用户,g表示组,o表示其他
对于访问规则的使用有如下几点是之前没有意识到的:
- 如果要操作一个文件,那么需要对该文件所属的每一级目录具有执行权限。区别目录的读权限和执行权限:读权限允许我们获取目录下的文件列表;写?执行吧?权限允许我们通过该目录(即搜索寻找特定文件)。例如PATH环境变量中的某个目录我们没有其执行权限,那么shell绝不会在该目录下找到可执行文件。
- 在目录中创建一个新文件,需要有该目录的写权限和执行权限
- 在目录中删除一个文件,需要有该目录的写权限和执行权限,但是不需要对该文件有读、写权限
- exec执行某个文件,必须是普通文件且有执行权限
对于文件和进程的权限匹配规则如下:
- 若进程的有效用户ID 是0(超级用户),则允许访问
- 若进程的有效用户ID等于文件的所有者ID,则根据访问权限判断是否可以执行。如果访问权限不允许执行,则结果就是不能执行。(注意此处不能再根据之后的规则判断是否有机会执行)
- 若进程的有效组ID或附属组ID 中的任意一个ID等于文件的所有组ID,则根据访问权限进行判断是否可以执行。(同样注意,如果ID想匹配,访问权限的判断结果就是最终结果)
- 其他用户访问权限设置判断是否可以执行
第八章 进程控制
8.2 进程标识
进程ID 标识符总是唯一的,但是可以被复用的,通常会采用延迟复用技术。系统中有一些专用进程,例如:
- ID:0,通常是调度进程,也被称为交换进程,是内核的一部分,不执行任何磁盘上的程序,属于系统进程
- ID:1,init进程在自举过程结束时,由内核进行调用,负责启动一个UNIX 系统:读取相关配置文件,并引导系统到一个状态。它是一个以超级用户特权运行的用户进程。
- init的程序文件通常在
/etc/init或者/sbin/init - 配置文件通常是
/etc/rc*和/etc/init.d文件夹中的文件
- init的程序文件通常在
- ID:2,页守护进程,负责支持虚拟存储系统的分页操作
除了进程ID 之外还存在其他标识符,所有标识符和获取标识符的方法如下
- 进程 ID
pid_t getpid(void) - 进程的父进程ID
pid_t getppid(void) - 进程的实际用户ID
pid_t getuid(void) - 进程的有效用户ID
pid_t geteuid(void) - 进程的实际组ID
pid_t getgid(void) - 进程的有效组ID
pid_t getegid(void)
上述函数都会没有出错的返回。
8.3 函数fork
一个进程可以通过fork创建多个子进程,但是没有函数可以返回进程的所有子进程,所以在fork的时候函数会向父进程返回子进程的ID,由用户自己来保存维护。
fork创建的子进程会获取父进程的数据空间、堆以及栈的副本,共享正文段。由于很多子进程并会使用大量的父进程的数据,而是会通过exec调用新的程序,所以会有写时复制的优化:父子共享父进程的数据空间、堆和栈,但内核将他们变成只读,如果父子进程尝试进行修改,内核只为共享的那块儿内存制作副本,通常是虚拟存储中的一页。
fork之后,父子进程的执行听从系统调度,没有明确的先后顺序,如果需要同步等操作需要信号量等辅助方式
注意I/O缓冲区的问题,Eg:printf函数在通向终端的时候是行缓冲的,但是通向文件的时候是全缓冲的,所以会造成如下的情况:
1 |
|
1 | (base) ➜ proc git:(master) ✗ ./fork1 |
父子进程共享文件
父子进程共享文件偏移量,可以轻松的实现子进程写入数据之后,父进程继续追加,但由于执行先后顺序的问题,容易输出混乱
fork失败的原因
- 系统中有太多进程了
- 实际用户ID的进程总数超过了限制
8.4 函数vfork
相比与fork,保证了:
- 并不将父进程的地址空间复制给子进程,而是真的共享
- 子进程先执行完,父进程再继续执行
8.5 函数exit
懒了,困了。。。
第十一章 线程
线程相关的api
线程的创建
1 | // 创建一个线程,需要注意的是该函数可能还没有返回,创建的线程就开始执行了 |
线程的终止
1 | // 例程直接return 或者调用pthread_exit |
线程阻塞
1 | // 本质上是一种屏障,底层也是通过锁来执行 |
综合Demo
1 |
|
线程同步
互斥量
读写锁
自旋锁
屏障
《操作系统导论》
CPU虚拟化--进程管理
进程与线程
进程
进程是资源分配的基本单位。
对进程的基本信息和运行状态的描述被称为进程控制块(Process Control Block,PCB),包含:
- 进程可以访问的内存(进程的地址空间)
- 一些特殊的寄存器:例如Program Counter(PC),Stack Pointer,Frame Pointer等
- 进程编号
- 进程状态
- 父进程编号
- 打开的文件列表
- 当前的文件夹
- 中断信息等
进程相关的API有:
fork()wait()exec()
线程
线程是独立调度的基本单位。
线程的切换必定发生上下文切换(context switch),不同于进程的切换,线程的切换会将状态信息保存在线程控制块中,并且地址空间保持不变(不需要切换当前使用的页表)。
一个进程中可以有多个线程,他们共享进程资源。
区别
- 进程是资源分配的基本单位,但线程不拥有自己的资源,他们可以访问隶属进程的资源。
- 线程是独立调度的基本单位,同一进程内的线程切换,不会引起进程的切换。
- 进程的创建和撤销以及切换过程开销远大于线程,从他们对应的资源上可以看出。
- 进程间通讯需要进程同步和互斥手段的辅助,以保证数据的一致性。而线程间可以通过直接读/写同一进程中的数据段(如全局变量)来通讯。
进程状态的切换
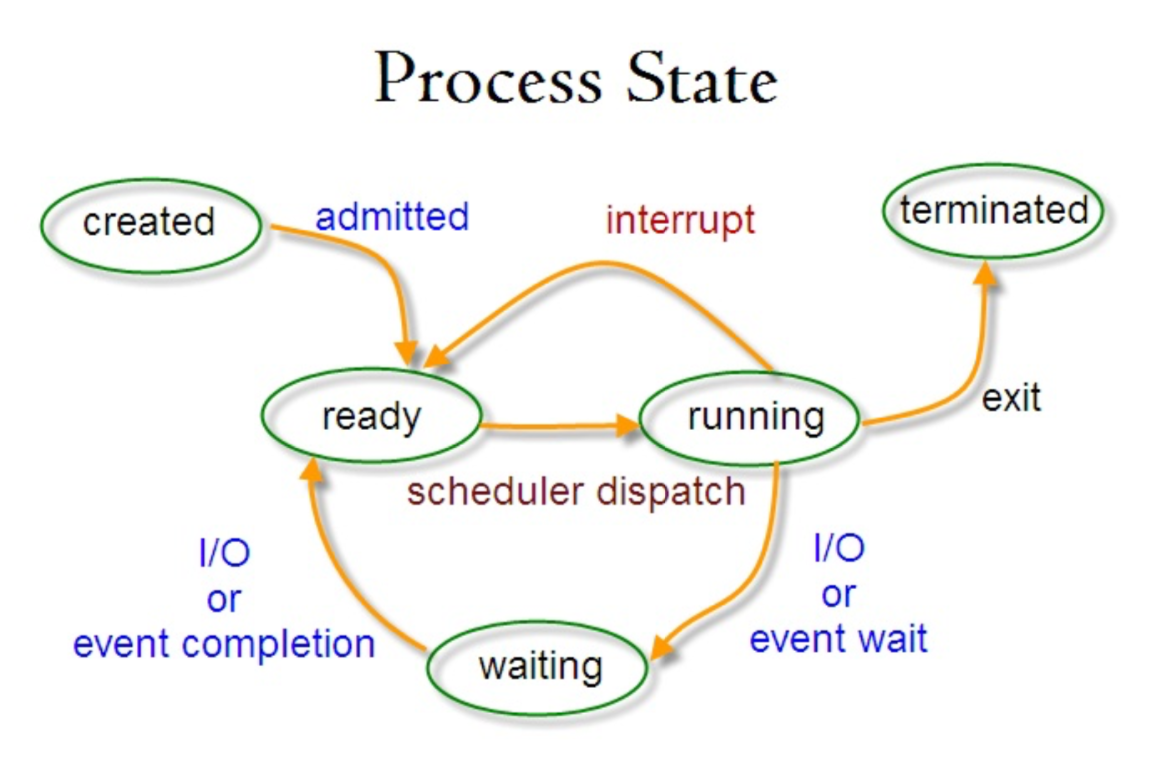
进程切换
操作系统在对CPU进行虚拟化的时候存在两点十分关键的挑战:性能与控制权。
- 性能:在不增加系统开销的情况下实现虚拟化
- 控制权:有效的运行进程,同时保留对硬件资源(磁盘,内存,cpu等)的控制权
为了实现高性能,用户的进程在被调度执行后,将会直接运行在CPU上,实现更高的性能。
受限制的操作(在进程和内核之间的切换)
为了实现控制权,硬件协助操作系统,提供用户模式和内核模式两种处理器模式。
- 在用户模式下,进程的不能执行特权操作,例如发出I/O请求或者执行受限操作。
- 在内核模式下,运行的代码(即操作系统或内核)可以执行他们想做的任何事情。
用户程序工作在用户模式下,如果需要系统调用,则通过内核暴露的陷阱指令,跳入内核,并将权限升级到内核模式,从而调用一些特权操作,完成后,操作系统调用一个特殊的从陷阱返回指令(return-from-trap),回到发起调用的用户程序中,同时权限降低到用户模式。
对系统调用的调用,看起来就像是一个过程调用一样,在过程调用中隐藏着著名的陷阱指令,它会将参数放入和内核约定好的位置中(如栈或者寄存器中),将系统调用号也放入其中,执行陷阱指令,之后处理陷阱指令的返回值,并将控制权返回给发出系统调用的程序。那么陷阱如何知道在OS内运行哪些代码呢?(用户程序在执行陷阱指令时不能指定要跳转到的代码地址),由操作系统在启动时设置陷阱表来实现,陷阱表中定义了在发生某些异常事件(如I/O中断、用户程序执行系统调用)时需要运行的代码,从而限制用户程序任意跳转到内核的任意位置。
整体流程如下:
- 操作系统初始化陷阱表
- 硬件记住系统调用处理程序的地址
- 操作系统在进程列表中创建条目,为程序分配内存,将程序加载到内存,根据argv设置程序栈,用寄存器/程序计数器(程序代码的入口位置)填充内核栈,从陷阱返回
- 硬件从内核栈恢复寄存器,转向用户模式,跳转到用户程序的入口
- 程序运行main,调用系统调用,陷入操作系统
- 硬件将寄存器保存到内核栈,转向内核模式,跳到陷阱处理程序
- 操作系统处理陷阱,做好系统调用工作,从陷阱返回
- 硬件从内核栈恢复寄存器,转向用户模式,跳转到陷阱之后的程序计数器
- 程序运行结束,通过exit()陷入
- 操作系统释放进程的资源,将进程从进程列表中清除
在进程之间切换
关键问题:如何让操作系统在没有执行的情况下重新获得CPU的控制权,来实现进程之间的切换。解决办法:
- 协作的方式(不可取):通过等待程序进行系统调用(陷阱,非法操作,yield),将CPU的控制权交还给操作系统
- 非协作的方式:利用时钟设备发出时钟中断,进入预先设置好的中断处理程序,从而回到内核态
时钟中断的处理流程如下:
- 操作系统初始化陷阱表
- 硬件记住系统调用处理程序&时钟处理程序
- 操作系统启动中断时钟
- 硬件启动时钟,每隔
xms中断CPU - 进程A,runnging
- 硬件发出时钟中断,将寄存器A保存到内核栈A,转向内核模式,跳到陷阱处理程序
- 操作系统处理陷阱,调用switch()例程,将寄存器A保存到进程结构A中,将进程结构B恢复到寄存器B,从陷阱返回(进入B)
- 硬件从内核栈B恢复寄存器B,转向用户模式,跳到B的程序计数器
- 进程B,running
时钟中断中存在两种类型的寄存器保存/恢复,如下:
- 发生时钟中断时,用户进程的用户寄存器由硬件隐式保存到该进程的内核栈。
- 当操作系统决定从进程A切换到B时,内核寄存器被操作系统明确地保存,但是存储到了该进程的进程结构的内存中。同时将B的进程结构中保存的数据恢复到内核寄存器,陷阱返回之后就如同刚刚是从B陷入了内核一样。
进程调度算法
度量指标
- 周转时间:任务完成时间-任务到达时间
- 响应时间:任务首次运行时间-任务到达时间
先进先出(First In First Out | Fist Come First Served)
先到的任务先执行,但很容易遇到长耗时任务在前,增加平均周转时间,这也被称为护航问题,为了解决长耗时任务在前的问题,引出了SJF。
最短任务优先(Shortest Job First)
耗时时间短的任务先执行,但这需要基于所有任务一起到来,同时已知每个任务耗时的假设。SJF可以在周转时间指标上达到最优,同时是不切实际的。
最短完成时间优先(Shortest Time-to-Completion First)
为了应对SJF中,所有任务不是同一时间到达的问题,提出了STCF,也被称作是抢占式SJF。每当新的工作进入系统时,会确定剩余工作和新工作中,谁的剩余时间最少,然后调度该工作。STCF相比于FIFO和SJF最大的特点是抢占式,在抢占式的条件下,SFCF在周转时间指标上可以达到最优。
时间片轮转(Round-Robin)
周期性的遍历每个任务一段时间,响应时间上是最优的,在周转时间上几乎是最差的。
多级反馈队列(Multi-level Feedback Queue)
在不知道进程到底需要执行多久的情况下,同时兼顾周转时间和响应时间,该算法思想仍存在于目前主流的操作系统的调度策略中。规则如下:
- 总是运行优先级高的任务
- 相同优先级的任务,轮转运行
- 工作刚进入系统时,放在最高优先级的队列中
- 工作用完整个时间片,降低一个优先级,工作在其时间片内,主动放弃CPU,优先级不变
- 经过一段时间S,将系统中所有的工作重新加入最高优先级,避免长工作会饥饿
- 一旦工作用完了其在某一层中的时间配额(无论中间主动放弃了多少次CPU),都降低其优先级,防止恶意程序在轮转中恶意调用IO,保持优先级。
MLFQ的问题,涉及到了太多需要依据经验来设置的变量,需要长时间的调优。
比例份额(彩票调度)
懒了
进程同步
经典同步问题
进程通信
内存虚拟化
分页式内存管理
并发
小蔡支持复习
进程间通信:管道(用户态和内核态之间的数据拷贝)、消息队列(用户态和内核态之间的数据拷贝&有结构的消息链表)、共享内存+信号量(无需到内核的数据拷贝操作)、信号(唯一的异步通信机制,例如ctrl+c)、Socket(TCP & UDP & 本地socket)
进程与线程之间的区别:具有相同的就绪、阻塞、执行三种状态以及状态转移关系、都可以实现高并发;进程是OS的调度单位而线程是CPU的调度单位、进程具有完整的资源平台、线程只独享寄存器和栈这种必不可少的资源;
协程:用户空间线程,由用户管理切换,例如python中的generator
线程池:频繁处理短时间任务或对响应时间要求敏感型任务
并行(多核) VS. 并发(时间片轮转&间隔执行)
互斥(不能同时进入临界区)VS. 同步(互相制约等待,执行顺序需要被保证)
锁(二值信号量) & 信号量 (生产/消费者;哲学家就餐;读者-写者)
悲观锁(自旋锁(一直申请,适合临界区很短) | 互斥锁(放入队列等待唤醒,适合临界区比较长) | 读写锁(通过前两种实现,分为优先读(只要不是写锁,就给读请求加锁)、优先写(有写请求就不能再给读加锁)和公平读写(通过一个flag的二值信号量实现排队)))
乐观锁(通过序列号,在写入时核对要写入的数据是否被修改过,典型的有数据库中的MVCC、在线文档多人编辑和GIT版本管理)
死锁的条件(互斥&请求并等待&不抢占&循环等待) & 死锁的处理方法(预防 | 避免 | 检测 | 解除),银行家算法(保证投资可回收)
- 互斥:一个资源每次只能被一个进程使用。
- 请求与保持:一个进程因请求资源而阻塞时,对已获得的资源保持不放。
- 不抢占:进程已获得的资源,在没事用完之前,不强行剥夺。
- 循环等待:多个进程之间形成一种互相循环等待资源的关系。
信号量 P操作:将\(seg-1\),如果\(seg<0\),进程或线程进入阻塞等待状态,否则继续; | V操作,将seg+1,如果\(seg<=0\),唤醒一个等待中的进程或线程。
基于信号量的生产/消费者:mutex用于控制互斥操作内存区域、emptyBuffers剩余的空闲位置、fullBuffers:可以消费的数量。生产者P(emptyBuffers) P(mutex) 生产 V(mutex) V(fullBuffers);消费者P(fullBuffers) P(mutex) 消费 V(mutex) V(emptyBuffers); | 哲学家就餐问题:偶数编号的科学家,先拿左筷子,再拿右筷子;奇数科学家,先拿右筷子再拿左筷子;统一先放左筷子再放右筷子; | 读者-写者(公平竞争):flag(用于控制读者写者排队)、rCountMutex(控制记录读者数量的变量)rCount(记录正在读的读者的数量)、wDataMutex(控制写者互斥)。读者:P(flag) P(rCountMutex) if(rCount==0) P(wDataMutex) rCount++; V(rCountMutex) V(flag) 读 P(rCountMutex) rCount-- if (rCount==0) V(wDataMutex) V(rCountMutex);写者:P(flag) P(wDataMutex) 写 V(wDataMutex) V(flag);
持久化(文件管理 & 文件传输)
文件管理:文件组成(索引节点(inode编号、存储位置、文件大小等等) | 目录项(文件名称,索引节点指针,与其他目录项的层级关系))磁盘格式化之后包含超级块(存储文件系统的详细信息)、索引节点区和数据块区; | 文件存储(管理被占用的数据块(连续空间存放、非连续存放(链表方式&索引方式)| 管理空闲数据块(空闲表法、空闲链表法和位图法)
I/O 传输(直接I/O;非直接I/O(内核态的缓冲区(PageCache),根据是否等待内核拷贝数据到应用程序缓冲区细分为同步和异步IO))
同步IO分为阻塞(等待拷贝完成)、非阻塞(立即返回拷贝是否完成的结果)和非阻塞I/O多路复用(见下,参考):
- select:不等待、主动轮询;\(2^{11}\) 个连接数量;
- poll:用链表突破了select的最大连接数的限制,可以支持更大的并发
- epoll:每1G内存10W连接,在poll的基础上,注册回调(该回调函数会将触发了注册事件的文件描述符放到链表中),提高并发能力。消息传递的方式:使用mmap减少复制开销(映射内核缓冲区到应用程序缓冲区);三个API(创建epoll实例(内部采用红黑树存储文件句柄,链表存储就绪的文件描述符)、注册监听事件、查询被触发的事件)触发方式有(level triger(水平触发,例如读缓冲区有数据就一直触发)和edge trigger(边缘触发,只会在读缓冲区数据变多(上升沿)时触发));Java JDK没有实现边缘触发、Netty重新实现的epoll机制,采用了边缘触发。
select和poll都需要用户手动遍历哪些文件描述符是就绪的。而epoll通过就绪链表,直接获取就绪的文件描述符
选择select还是epoll的角度:连接数量 & 活跃数量的占比
传统IO:磁盘文件 -(DMA)-> 内核缓冲区-(CPU) -> 用户缓冲 -(CPU)-> socket 缓冲区 -(DMA-)> 网卡 (4次切换,4次拷贝)零拷贝:两次切换,两次拷贝。适合小文件(不会长期占用缓存区)& 不需要修改
数据库
Gap锁:某个范围内允许删除,但不能插入
索引 数据结构
主键索引 & 非主键索引
覆盖索引(等价于联合索引)(主键索引+二级索引)可以避免回表(根据二级索引找到主键,根据主键找到磁盘位置)
自适应索引
主键 -> 主键索引
- 写文件的时候,为什么需要将用户的缓冲区拷贝到内核态?
参考书籍
- 《操作系统导论》不是自己买的书,留个底,方便之后想查。豆瓣 操作系统导论

- 《UNIX 环境高级编程》